
Solve Your Data Access and Resource Capacity Constraints
LEARN HOW TO CONSTRUCTIVELY APPLY AN EXPERIMENTATION BASED METHODOLOGY USING THE ECOSYSTEM.AI WORKBENCH OR NOTEBOOKS.
Introduction #
This lesson consists of step-by-step actions that can be taken in the ecosystem.Ai Platform. Learn how to constructively apply an experimentation based methodology, accurately configure settings in the Workbench or Notebook, and set up simulations to test hypotheses. Follow the guide to then analyze and monitor the in-process results of your live experiments using Dashboards.
Experimentation should be an integral part of every Data Science job. The Data Science Experimentation Module is designed to allow you to overcome common difficulties associated with the data science process:
- DATA ACCESS – Waiting for data to be accessible for modeling, or to be available in production for scoring, is a serious bottleneck in most processes. There could also be a distinctive lack of data for new use cases, forcing a cold-start scenario which might be uncharted territory.
- RESOURCES – There are not enough data scientists that are needed to build all of the models across an organization.
- TIME DEPENDENCE – If the customer context is time dependent this adds additional constraints to the turnaround time.
The Data Science Experimentation Module is designed to allow you to add intelligence to your process. Learn and rapidly iterate while the traditional data science process is being completed. It also has sophisticated functionality to take time dependence into account
How it Works #
The Data Science Experimentation Module uses real-time feedback to learn how to more effectively rank vidgets (offers).
The real-time feedback learning system can be activated with or without data, how this is done depends on the availability of your data. Whether there is none available, or using data on user context (demographic, behavioral, etc.) and historical behavior.
Each time a user interacts with the real-time feedback learning system, that interaction is logged. Every logged interaction then advances the state of knowledge of the system. This knowledge can be further used to enhance the effectiveness of the traditional data science process, if running in parallel. Ensuring effective learning without focusing too extensively on a single option through testing.
The system uses an experimentation based methodology, which is a testing approach to presenting vidgets (offers) to customers. Rather than selecting just one solution and missing the opportunity to explore the rest, experimentation allows you to run multiple tests at the same time. The vidgets to experiment with could be in the form of products, customer engagement messages, design constructs, special offers, and more.
About Data
The Data Science Experimentation Module does not require any data to be available, but can incorporate additional data as and when it becomes available.
Starting without data does not affect the activation of the experiment, all that is required is a list of vidgets (offers). Having no data could be due to opting in for a cold-start scenario, such as if a new product is being launched and there is no historical data available. It could also be due to capacity and/or technical constraints associated with access to the needed data.
If data is available in addition to the vidget list, it can help to improve the effectiveness of the system’s learning. If segmentation variables are available those can be used to add context to the learning. Context can also be set at a customer level for truly personalized predictions. If historical data is available it can be used to provide a more informed starting point for the experiment.
Time Dependence
Systems involving human behavior will always be affected by time.
Time alters human behavior for a number of reasons: evolving trends, communal rituals, personal events and environmental changes. These changes are often not consistent, and will therefore happen at varying points in the time scale.
The Data Science Experimentation Module incorporates a range of functionality, allowing human changes to be captured and effectively taken into account:
- Real-time learning – In the moment capture of activity.
- Sophisticated forgetfulness – Vidget level options that can be set based on applications, and adjusted as the application is running.
- Repeated customer interactions – Sophisticated options that account for human ritual. Tuned based on applications, and adjusted as the application is running.
Let’s Get Started! #
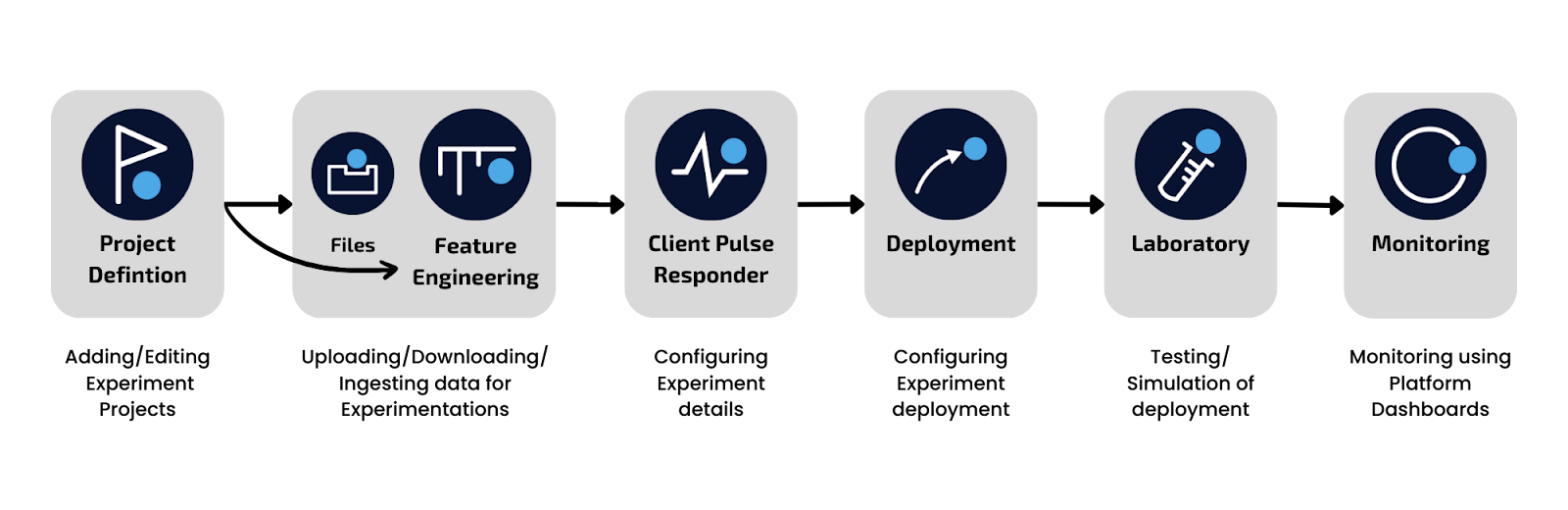
Two main interfaces can be used to access the ecosystem.Ai functionality. The first is the Workbench graphical interface and the second is using Jupyter Notebooks. This lesson takes you through the Workbench configuration for experiments.
If you would prefer to build your experiment in a Notebook, head to Dashboard, and click on the Jupyter Notebooks icon. From there, navigate to Documentation, Get Started and find “Get Started Experiments”.

Projects #
Projects are where you will make, manage and keep track of all of the work linked to the completion of any particular deployment project.
When you log into the Workbench you will see example projects that have already been created for you in the Dashboard and Projects sections.
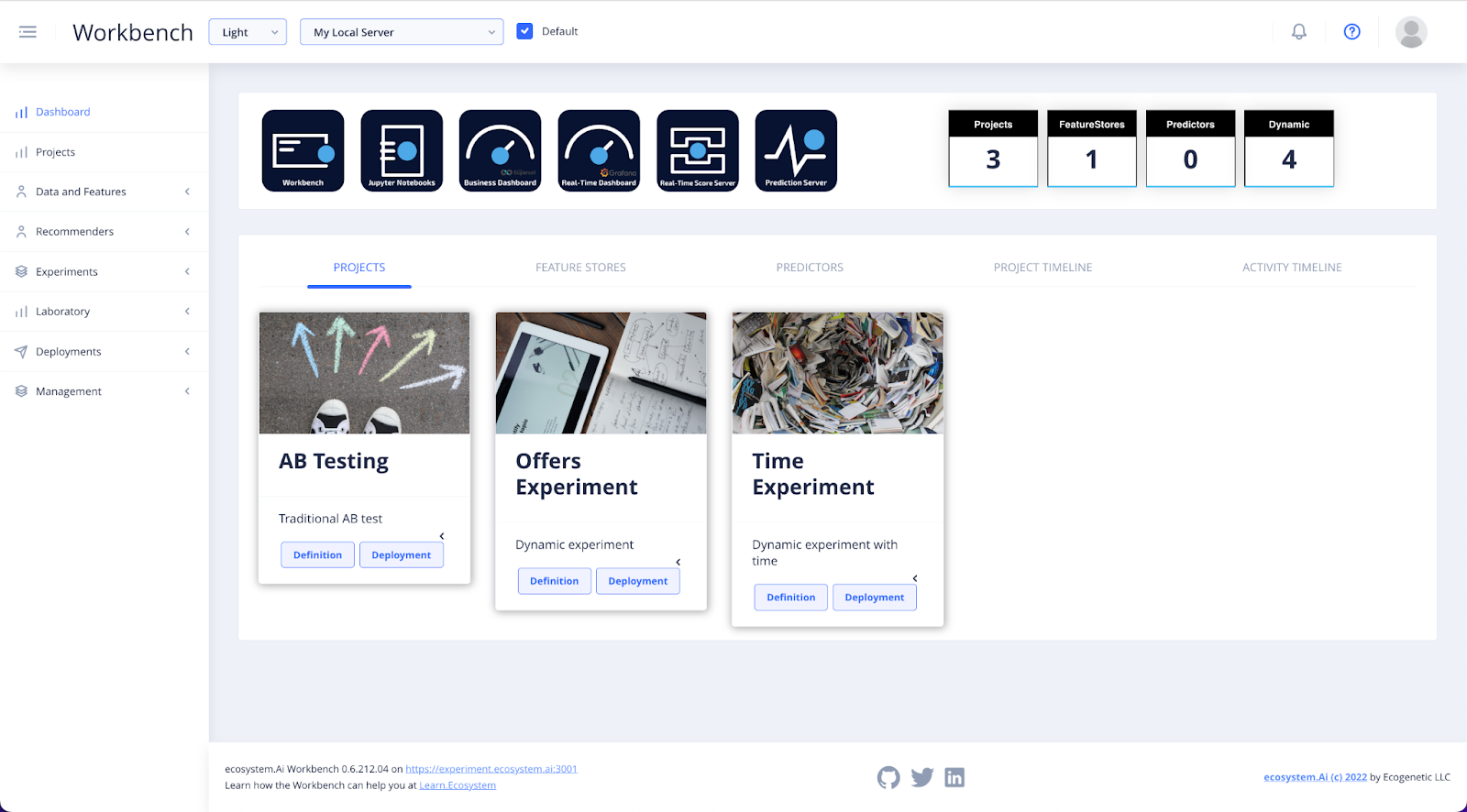
You can edit these projects to set up your own pre-configured first example.
Some of the example projects that have already been set up for you are:
- Basic AB Testing
- Offers Experiment – which uses no historical data
- Time Experiment – that utilizes the full functionality for handling time dependence.
In Projects, you can either edit an existing project or add a new one.
To view or edit a project, click on the project name. A section will open below the project list with all the project details.
To create a new project, select + Add Project.
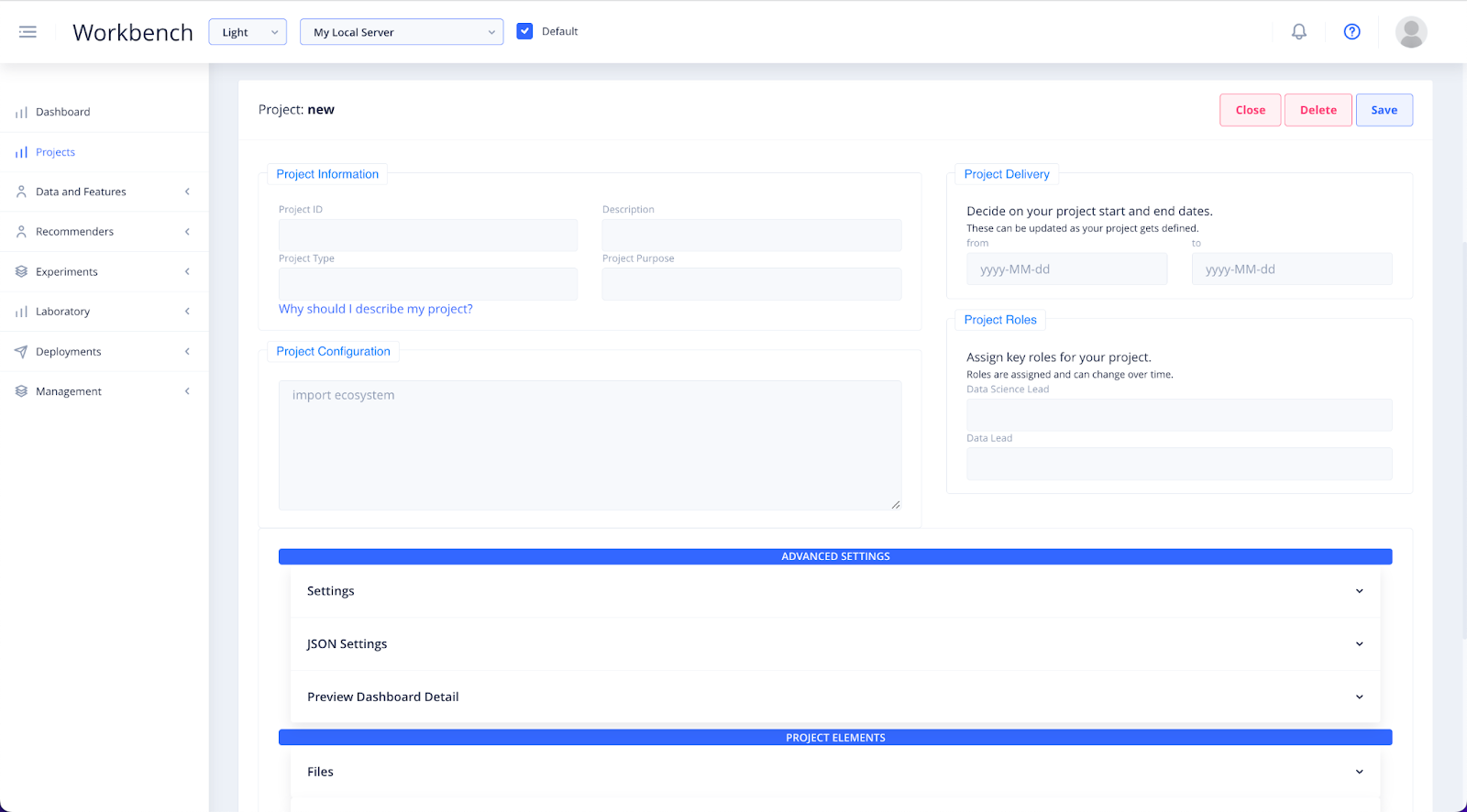
A section will open below the project list where you can input the details of your new project. In Project ID specify a name that everyone in your team can relate to. Add an accurate Description and provide an indication of the Type (eg. Experiment). Specify the Project Purpose (eg. ). You can also assign dates and humans to the project. This is more for administrative purposes than a necessity.
The Projects Elements dropdowns are for administrative purposes only.
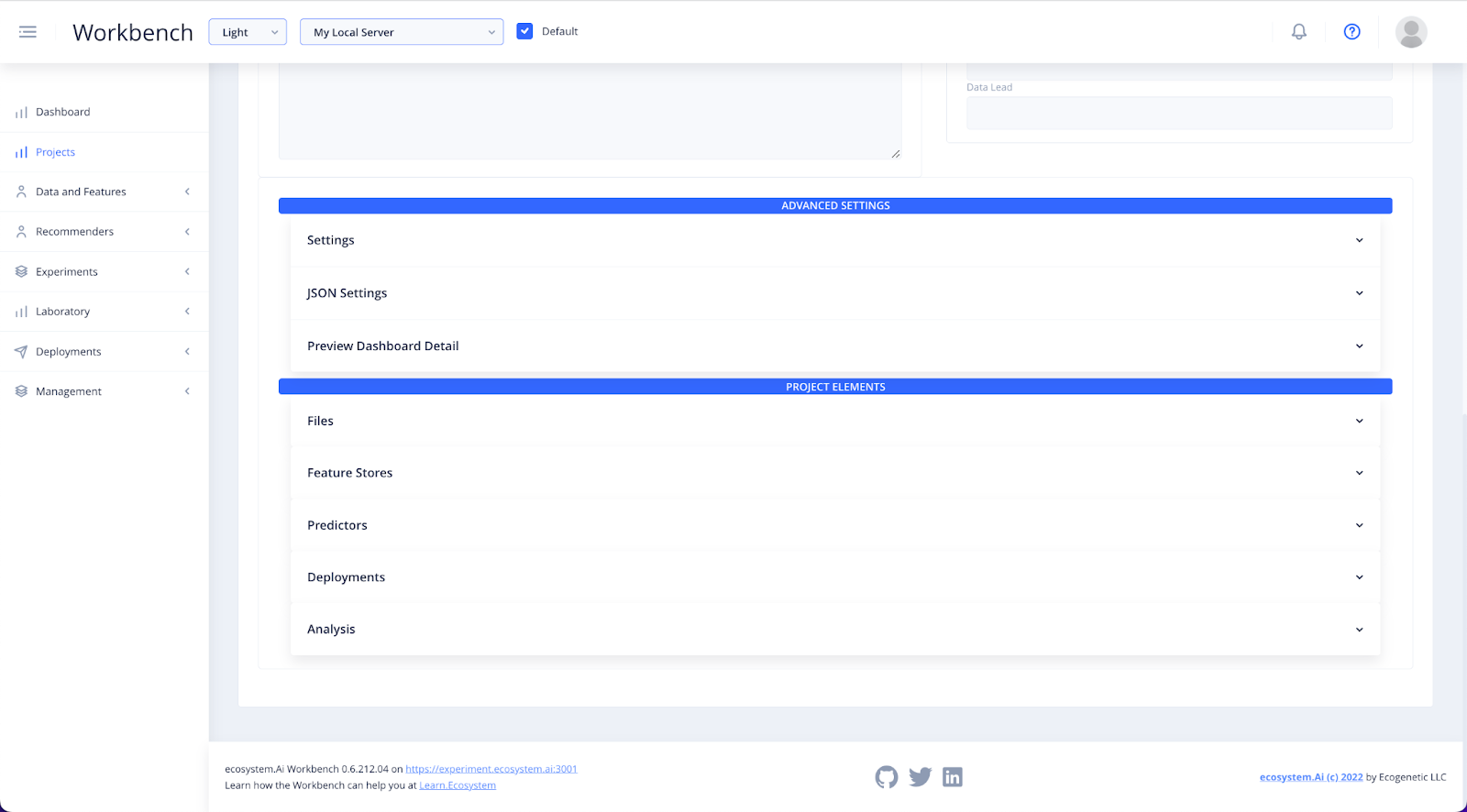
Adding Files, Feature Stores, Predictors, Deployments and Analysis files here will only add the names of the files, not the files themselves.
As you progress with your experiment configurations, you will link items to the project as they are created. Such as the simulations and other elements.
Manage Files and Feature Engineering in Data and Features #
The data used to configure your data science experiment can range from just a list of vidgets (offers), to a full set of customer-level data with historical behavior. Examples of different styles of experiment data sets can be found in the example projects.
Add Data to the ecosystem.Ai Platform
In the Data and Features section of the Workbench, you will find Manage Files.
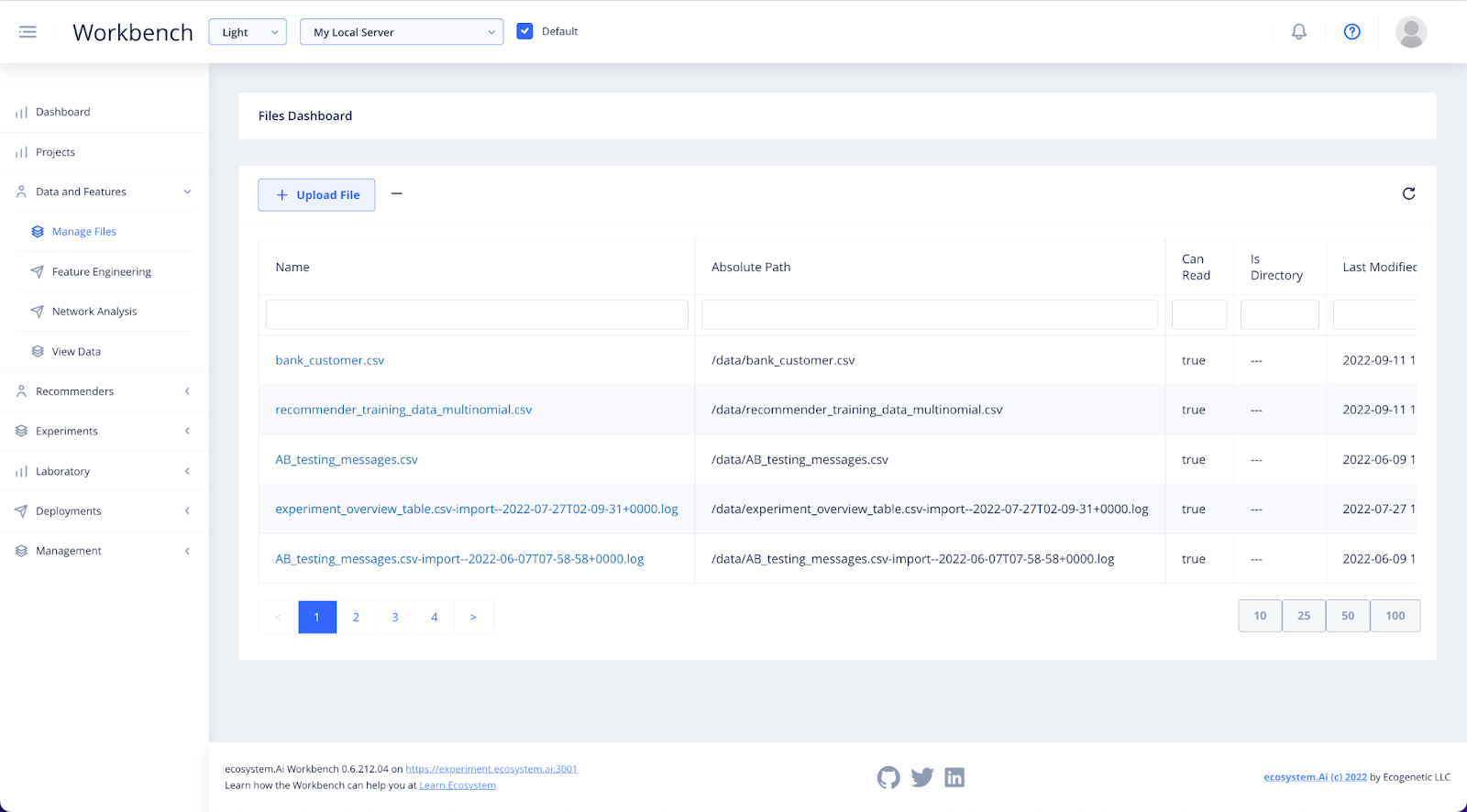
Here, you will be able to add, view, delete and download the data files available for you to build predictions with.
To upload a file of your own, select + Upload File.
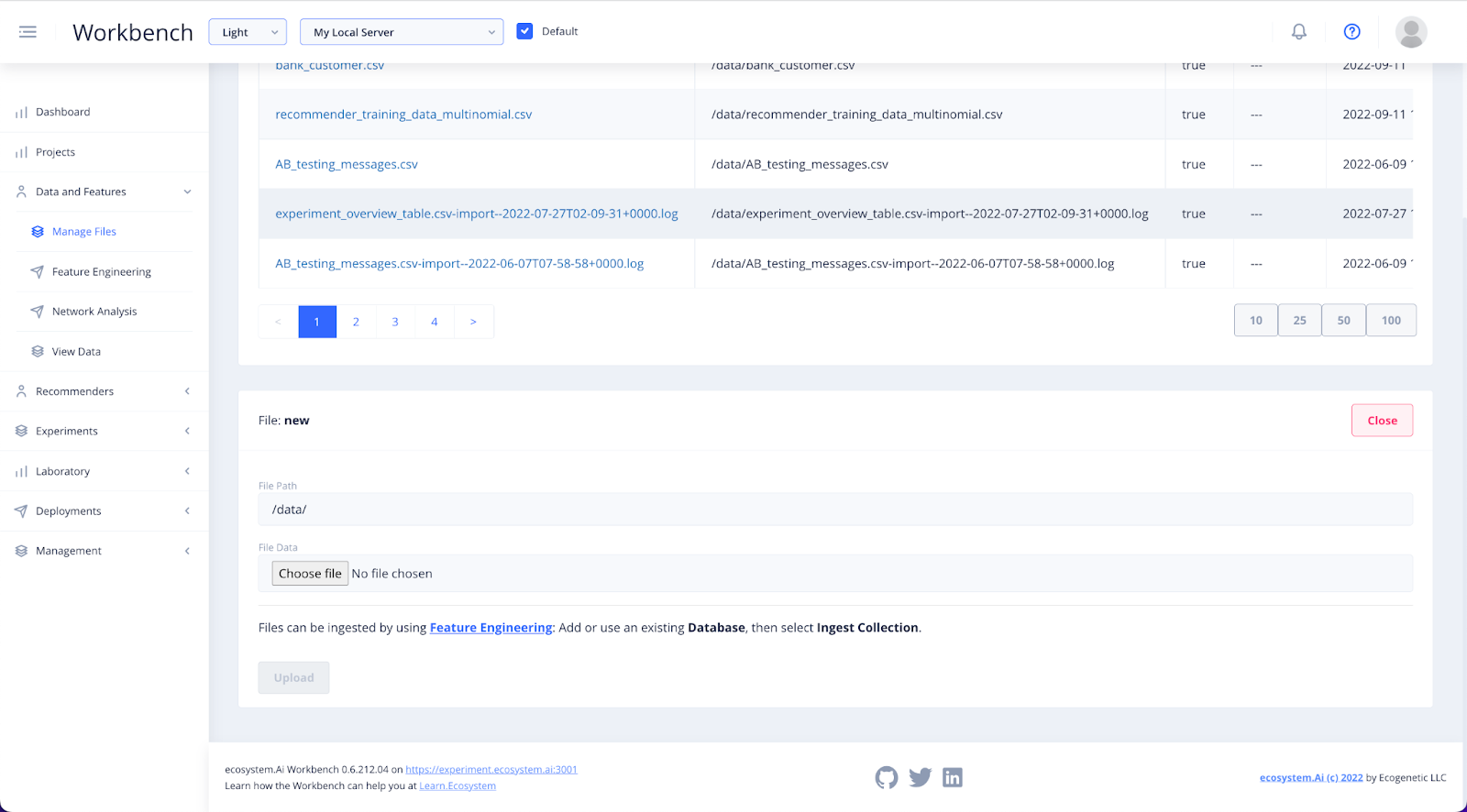
A section will open below the files list where you can input the details of your upload. Files must be uploaded in either CSV or JSON format. Upload and then refresh, the file will appear in your files list.
To download a file, click on the file name.
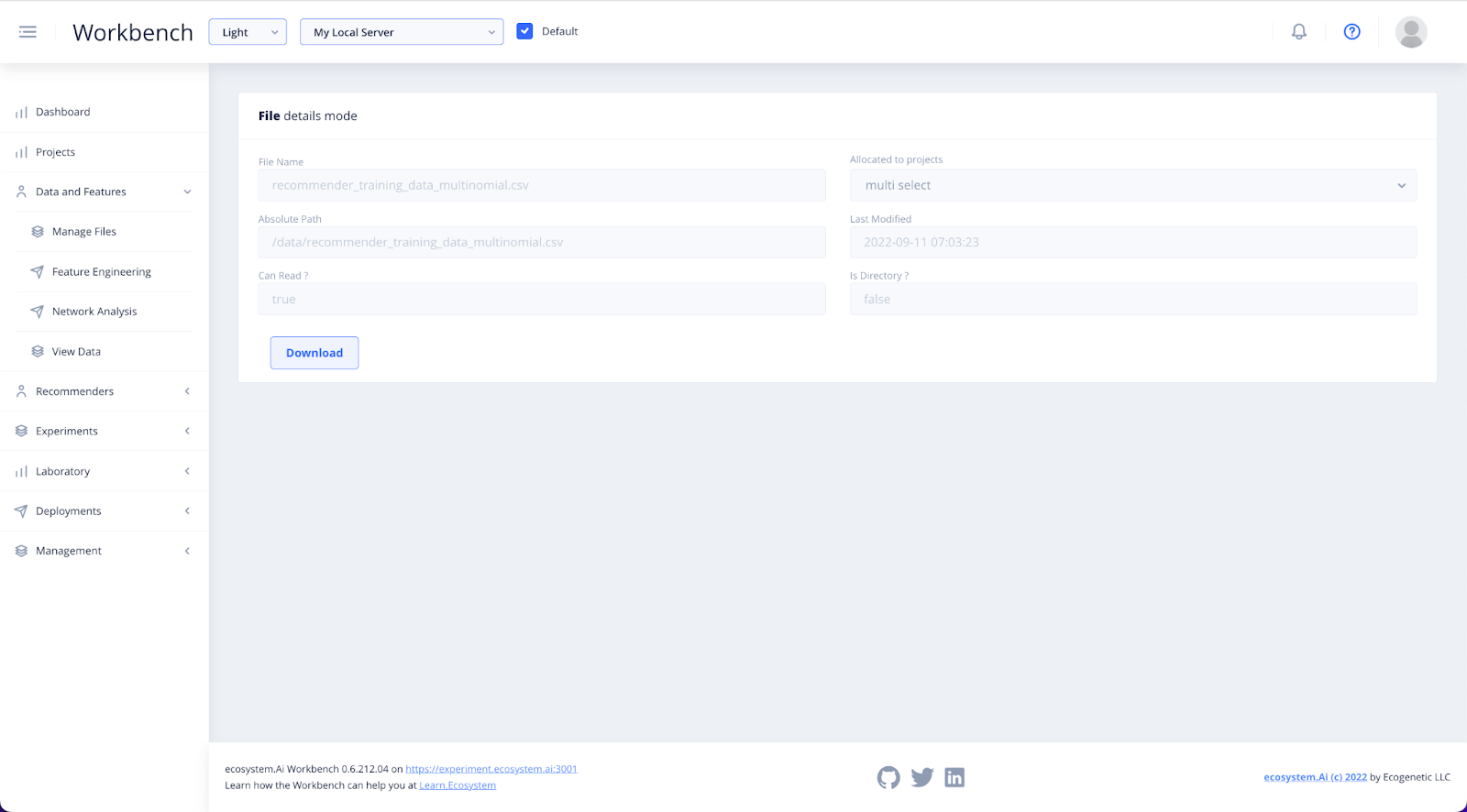
A section will open up where you can view the details of your download. Click Download and select your download location.
To delete a file, click Delete to the right of the file name.
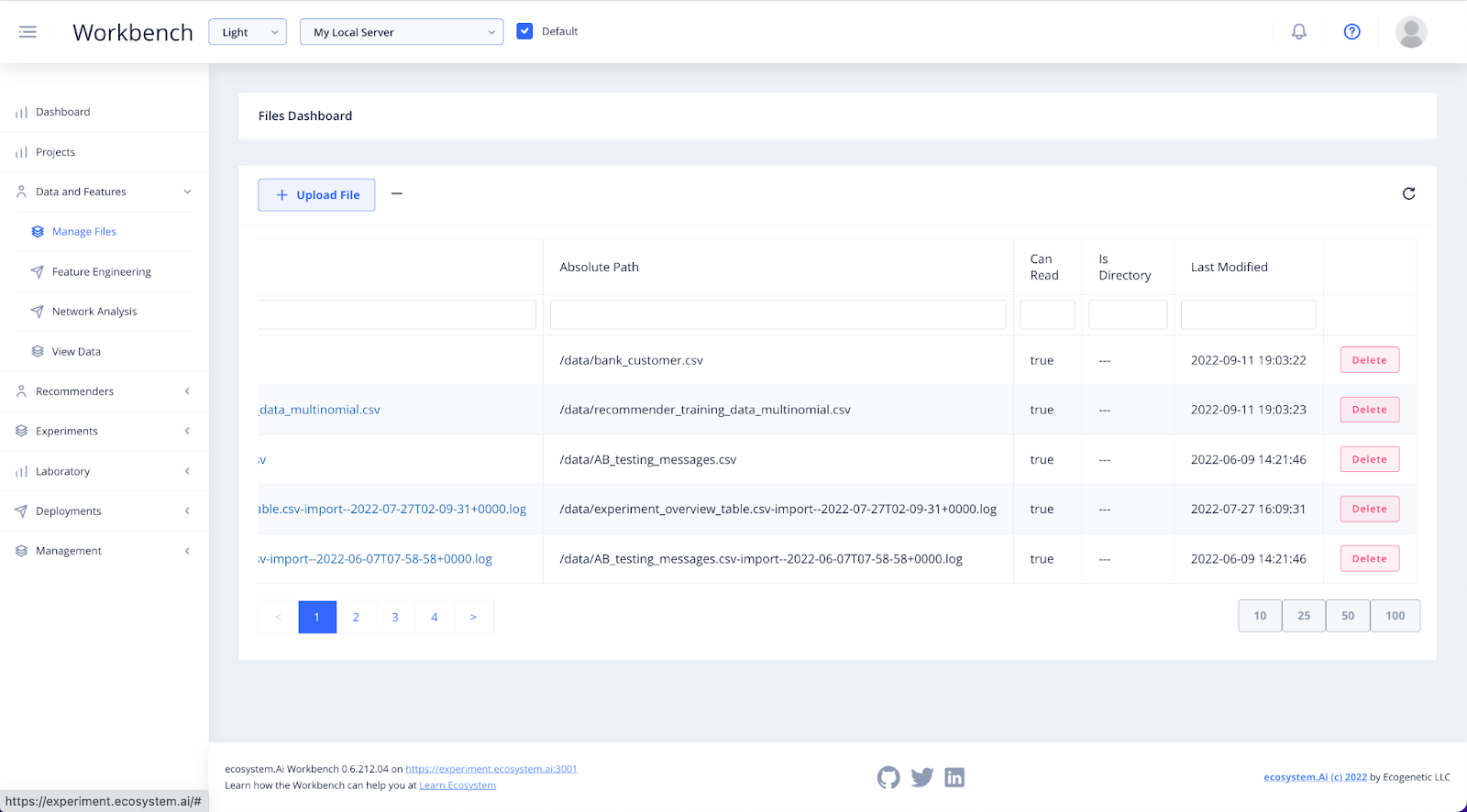
Deleting a file from here will remove the file from all projects whether active or inactive.
Connect a Database
In the Data and Features section of the Workbench, you will find Feature Engineering. Add a database using connection strings with the Presto Data Navigator.
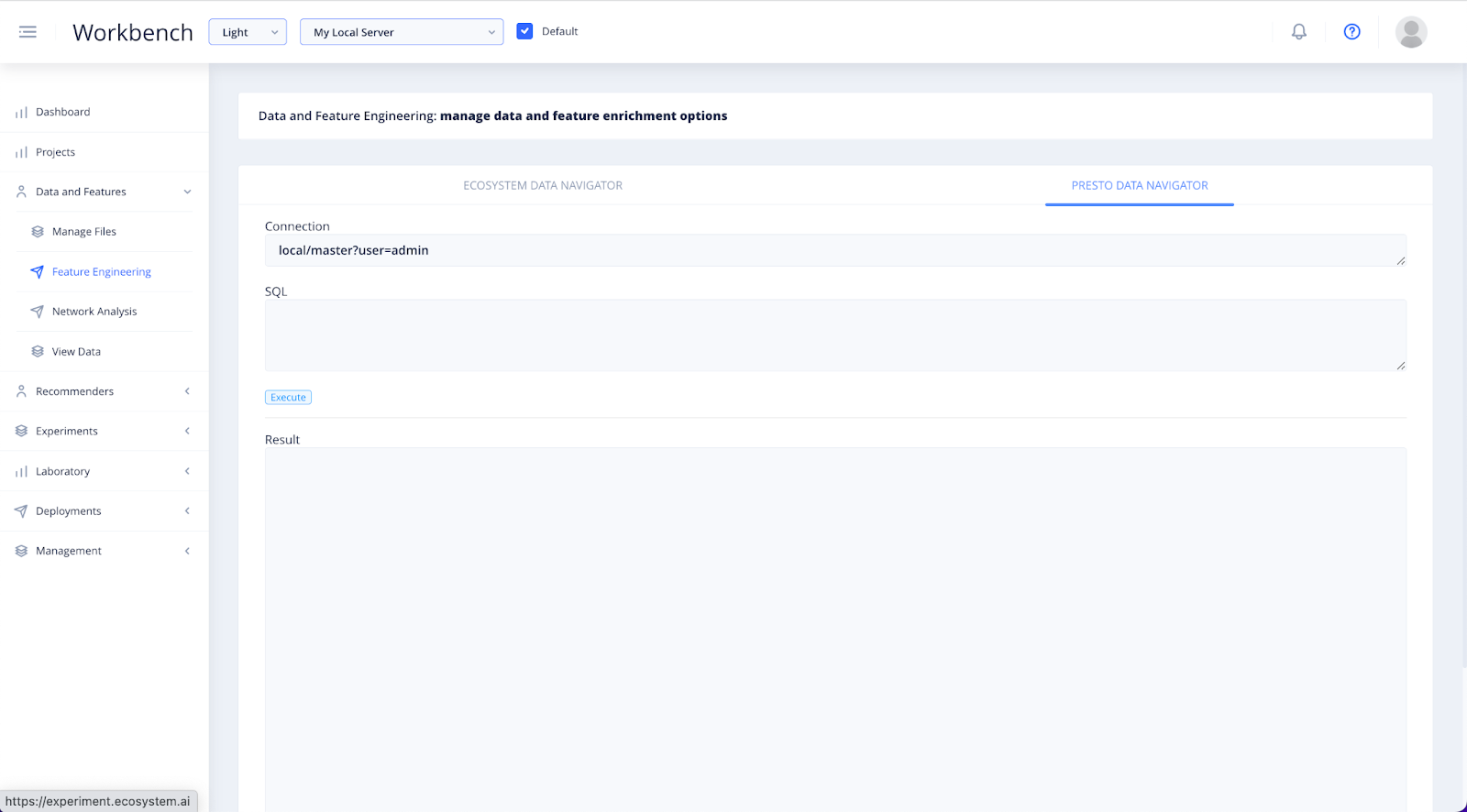
If you have your own database, you can connect it here. This database access option uses the Presto Worker in the platform. Add a Connection path, similar to this example: local/master?user=admin. Then write a SQL statement to extract the data you want, similar to this example: select * from master.bank_customer limit 2. Then click Execute.
NOTE: IN ORDER TO ADD DATA USING THE PRESTO FUNCTIONALITY, YOU MUST FIRST HAVE YOUR PRESTO CONNECTION ACCURATELY SET UP.
Ingest Data into the Workbench
Ingest data to be used in your projects with the Ecosystem Data Navigator.
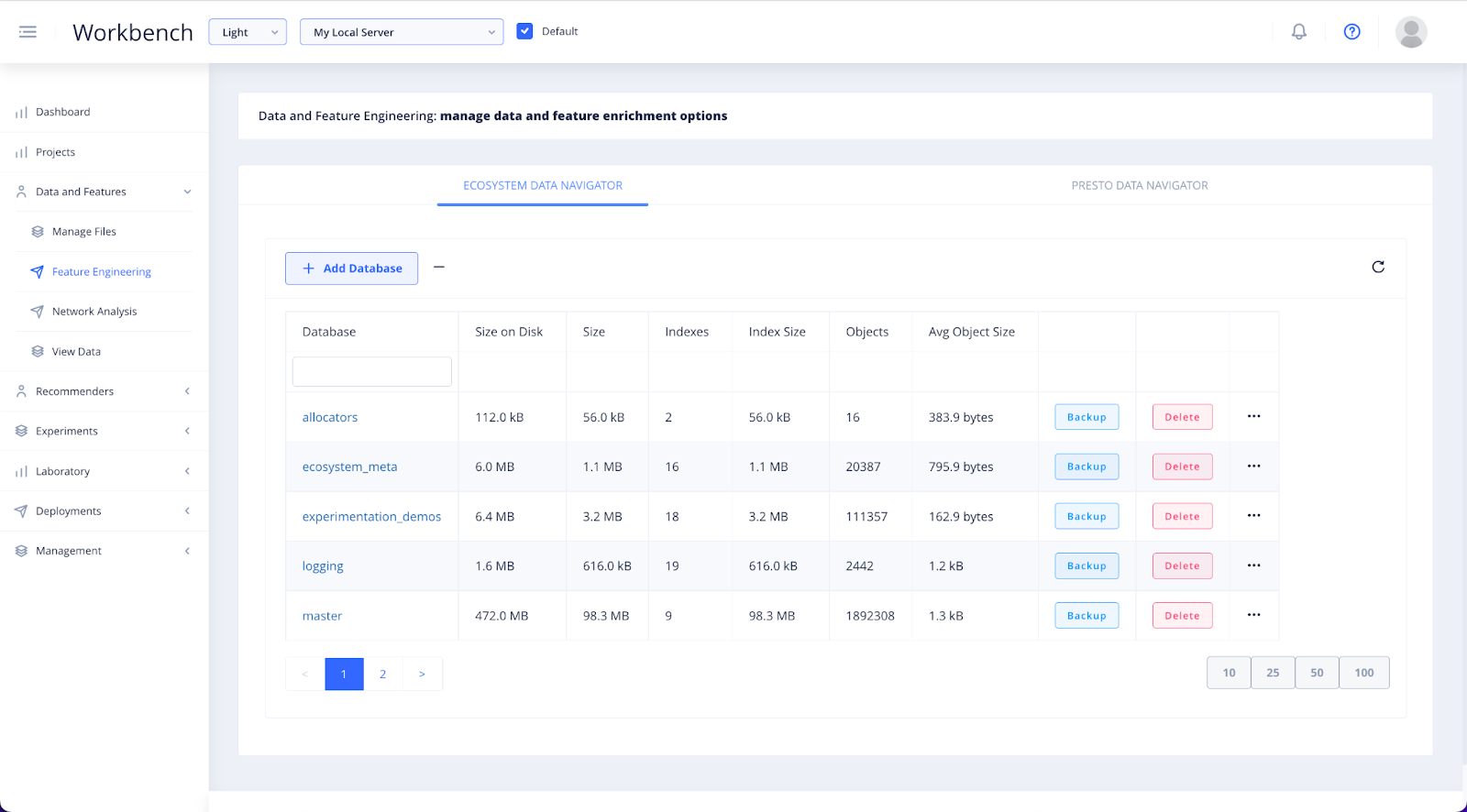
Once data has been added to the Platform it must be ingested into a specified database and collection.
You can either select a database and ingest your file into it. Or to create a new database, select + Add Database.
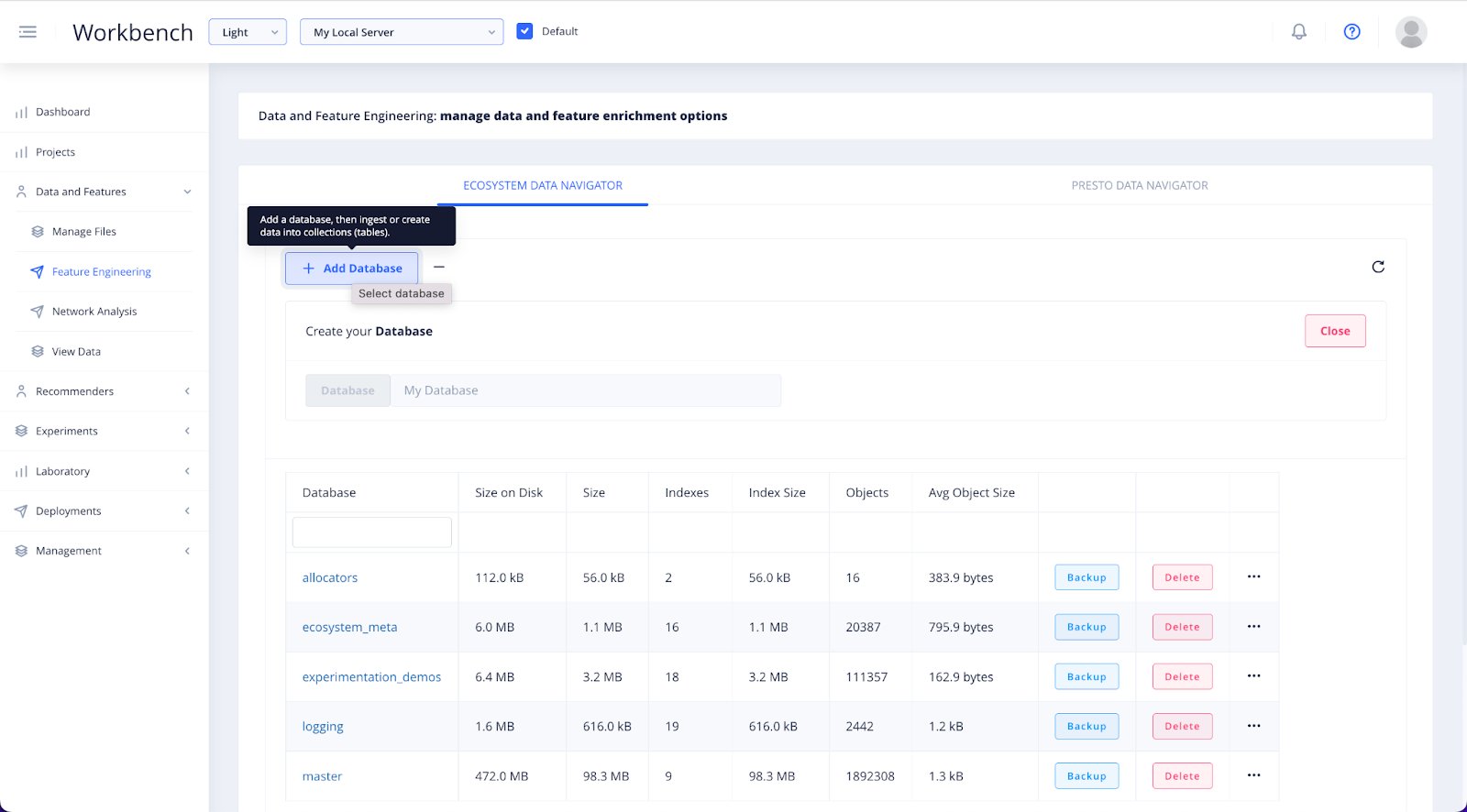
Add a unique database name related to your project. Click the Database button to the left of the input field to create it.
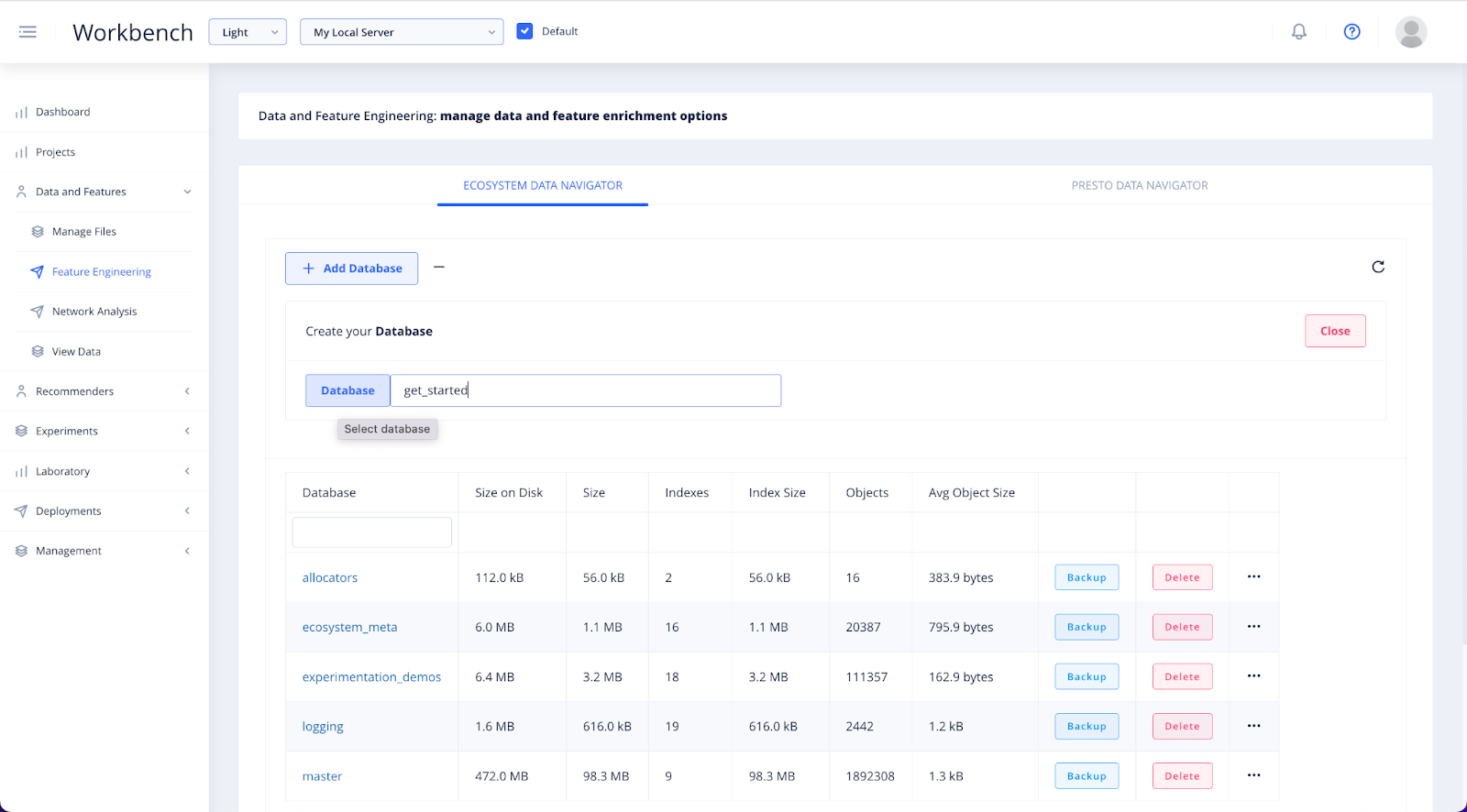
Once your database has been created, refresh the database list and click into it.
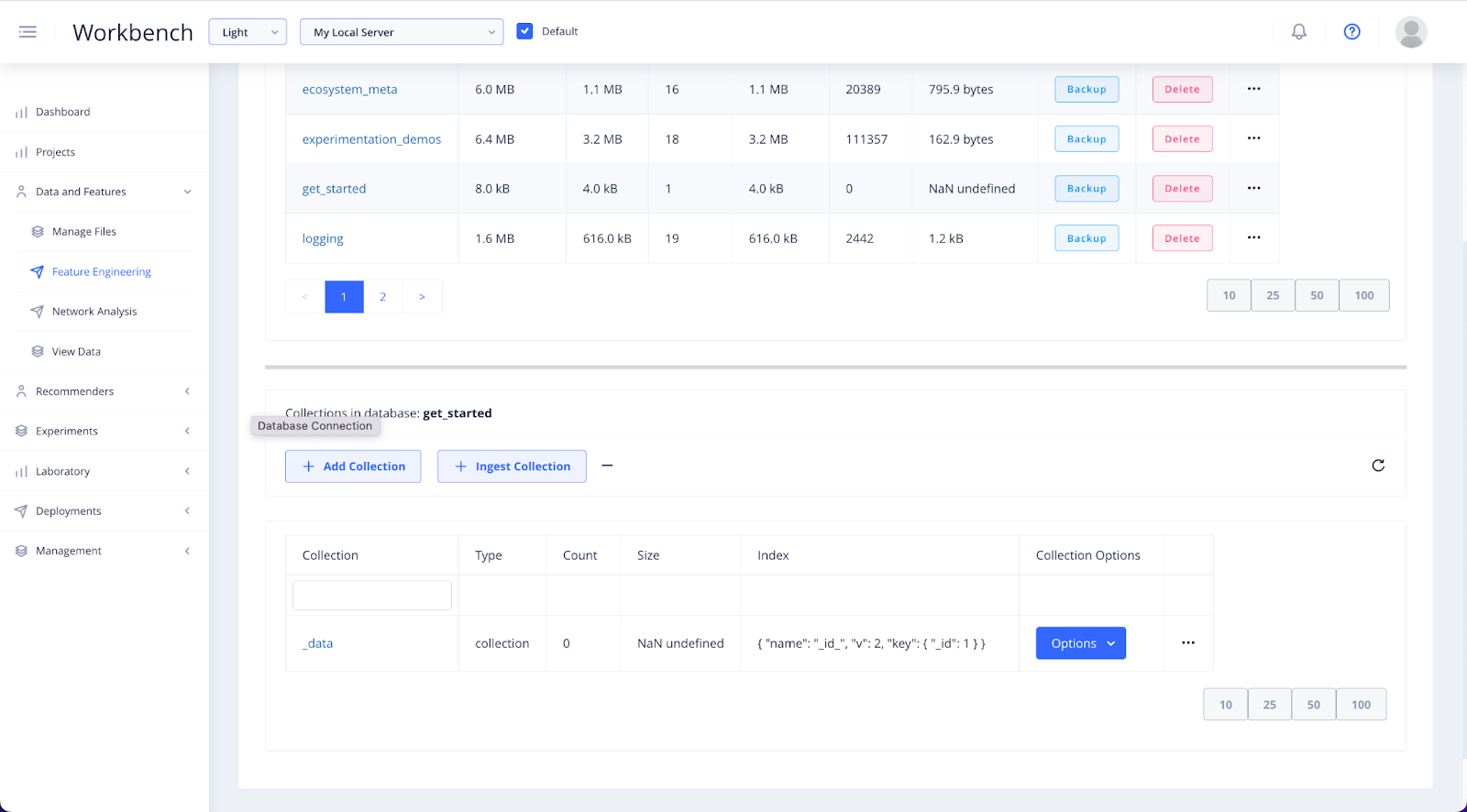
To ingest your file as a new collection inside your chosen database, select + Ingest Collection.
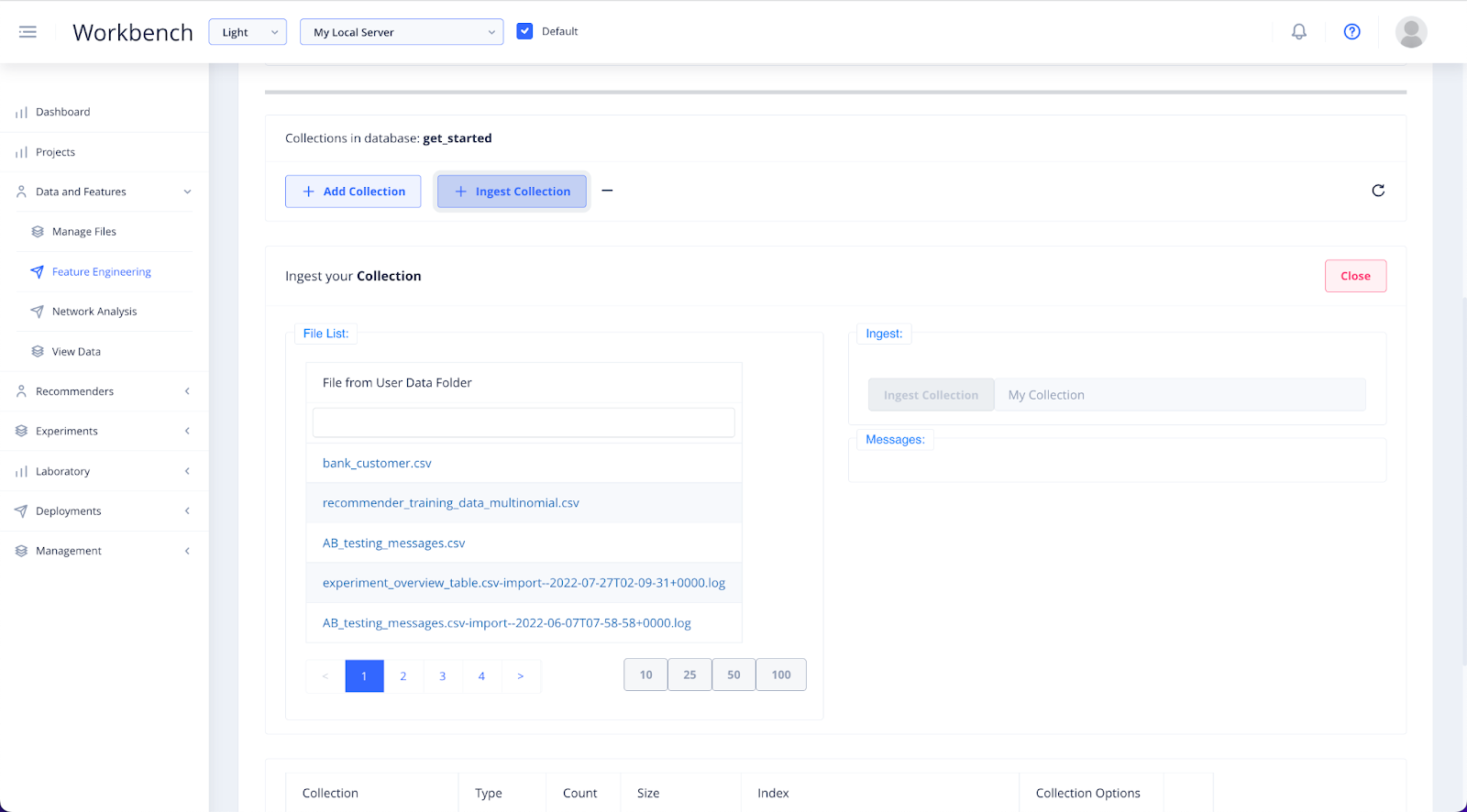
Select your file from the file list.
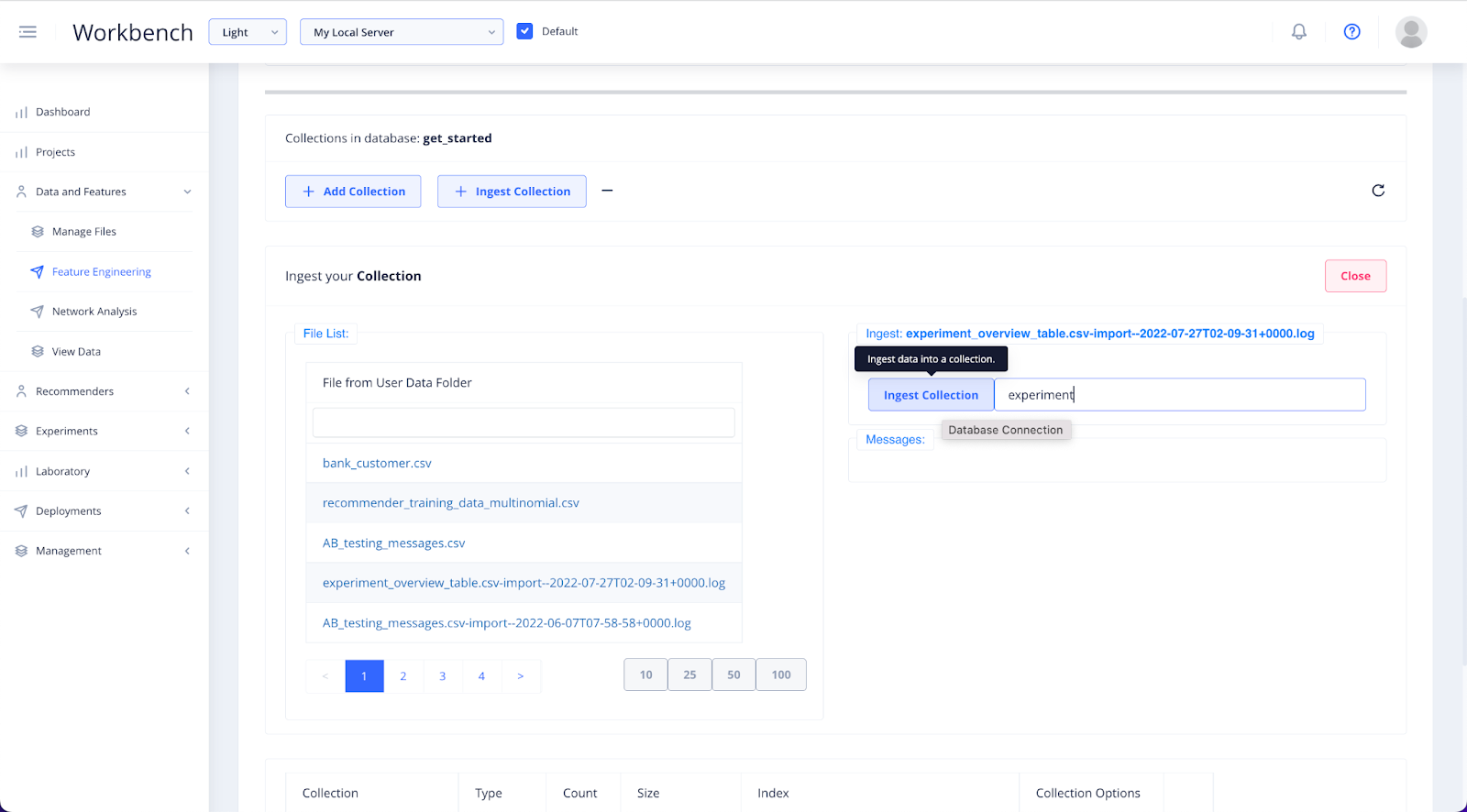
You will see the file name appear above the ingest: input field. Either copy this name or choose a unique one related to your project, then click Ingest to the left of the input.
NOTE: IF THE NAME OF THE COLLECTION YOU ARE INGESTING ALREADY EXISTS, THE NEW DATA WILL BE APPENDED TO THE EXISTING DATA. It will not replace the existing data

Dynamic Pulse Responder Experiment Configuration #
Dynamic Experiments allows you to configure the specifications of your experiment. This includes configuring the options you want to test and how you want to balance the exploring and exploiting in your learning approach. You can also configure how much detail from your data you are going to use, and how the experiment should handle changes in human behavior over time.
Note: Most of the settings in this section can remain default.
View and Add your Experiment Configurations and Settings
In the Experiments section of the Workbench, you will find Dynamic Experiments.
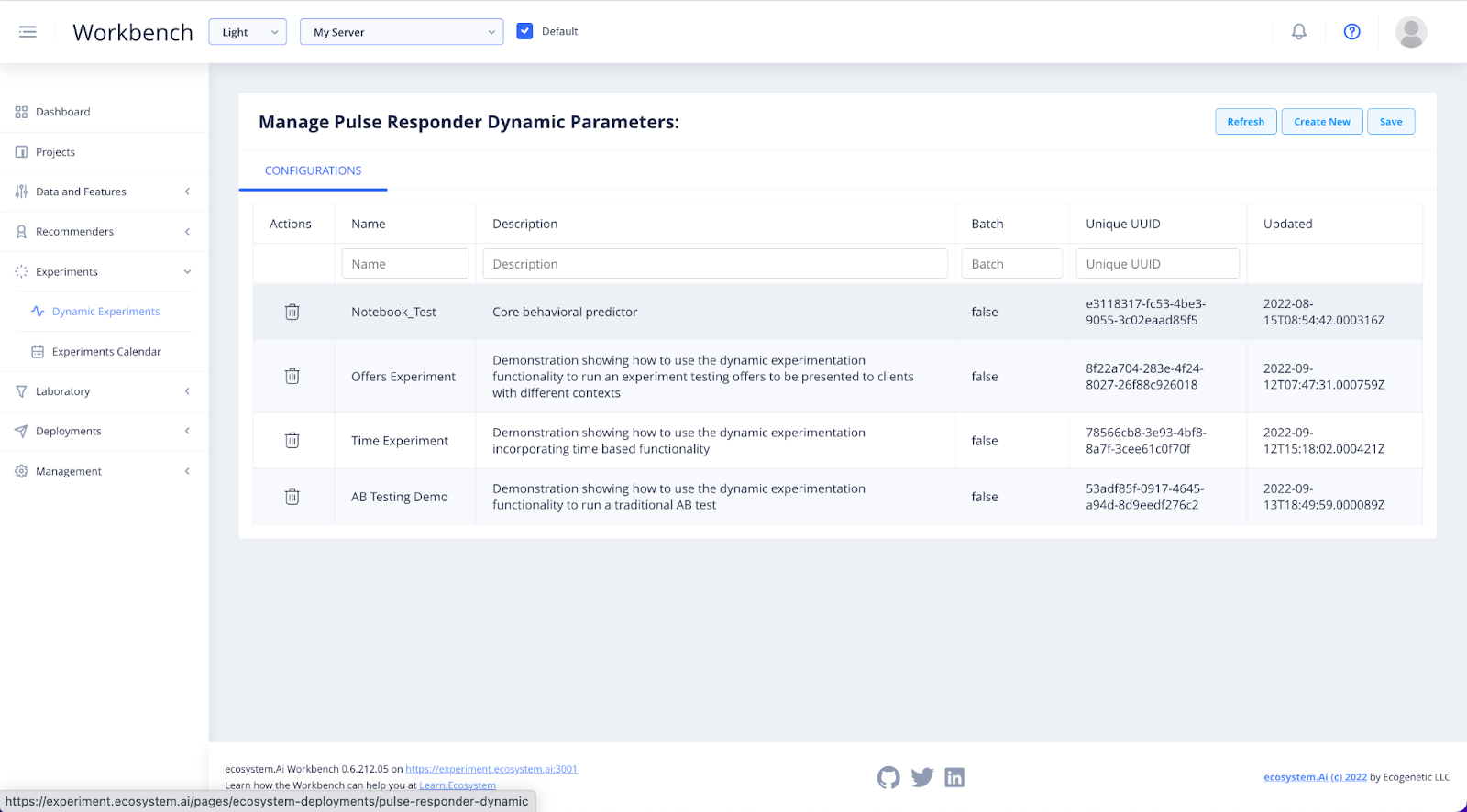
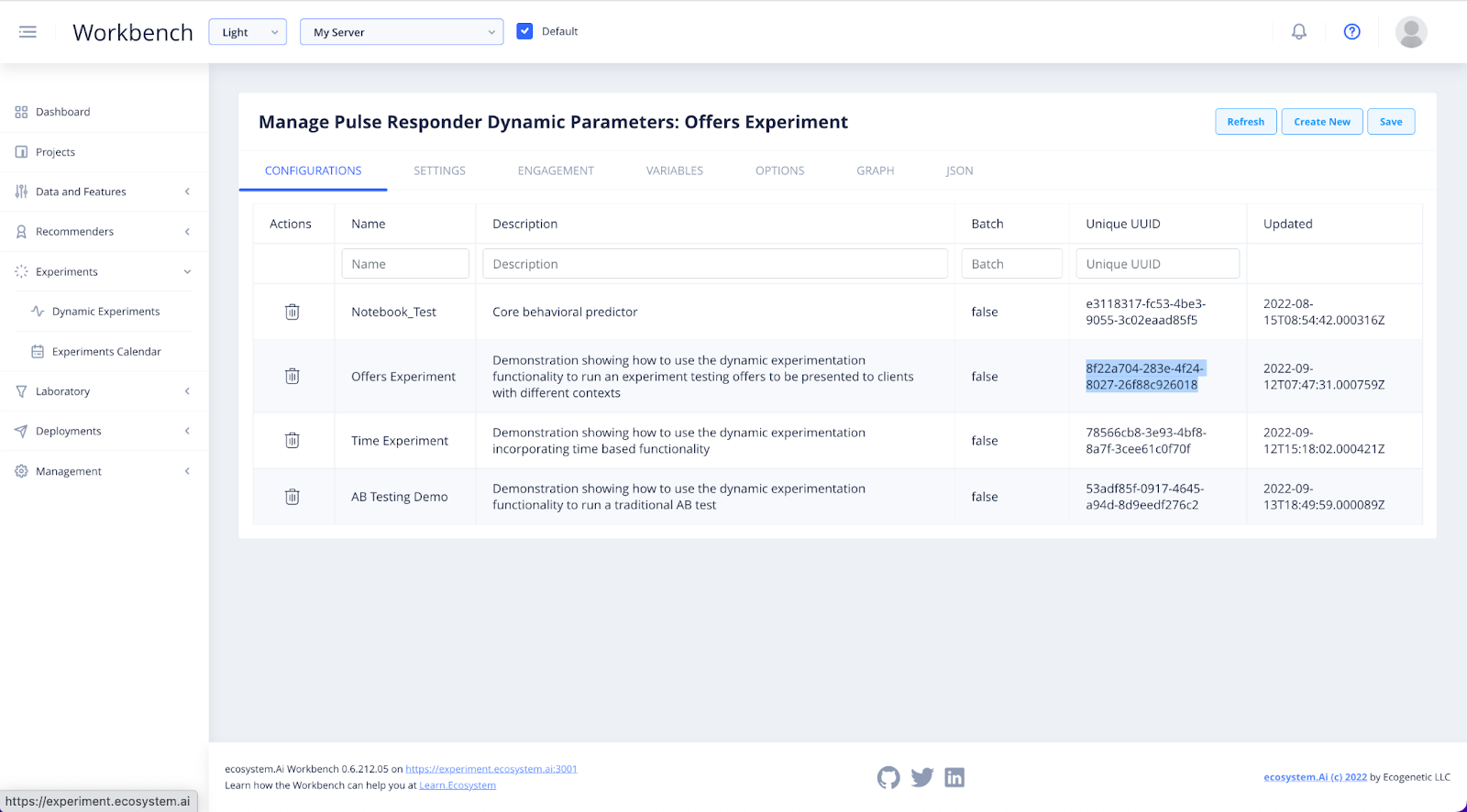
Here you will find a list of all of the existing experiment Configurations. To view or edit the details, click on the experiment name.
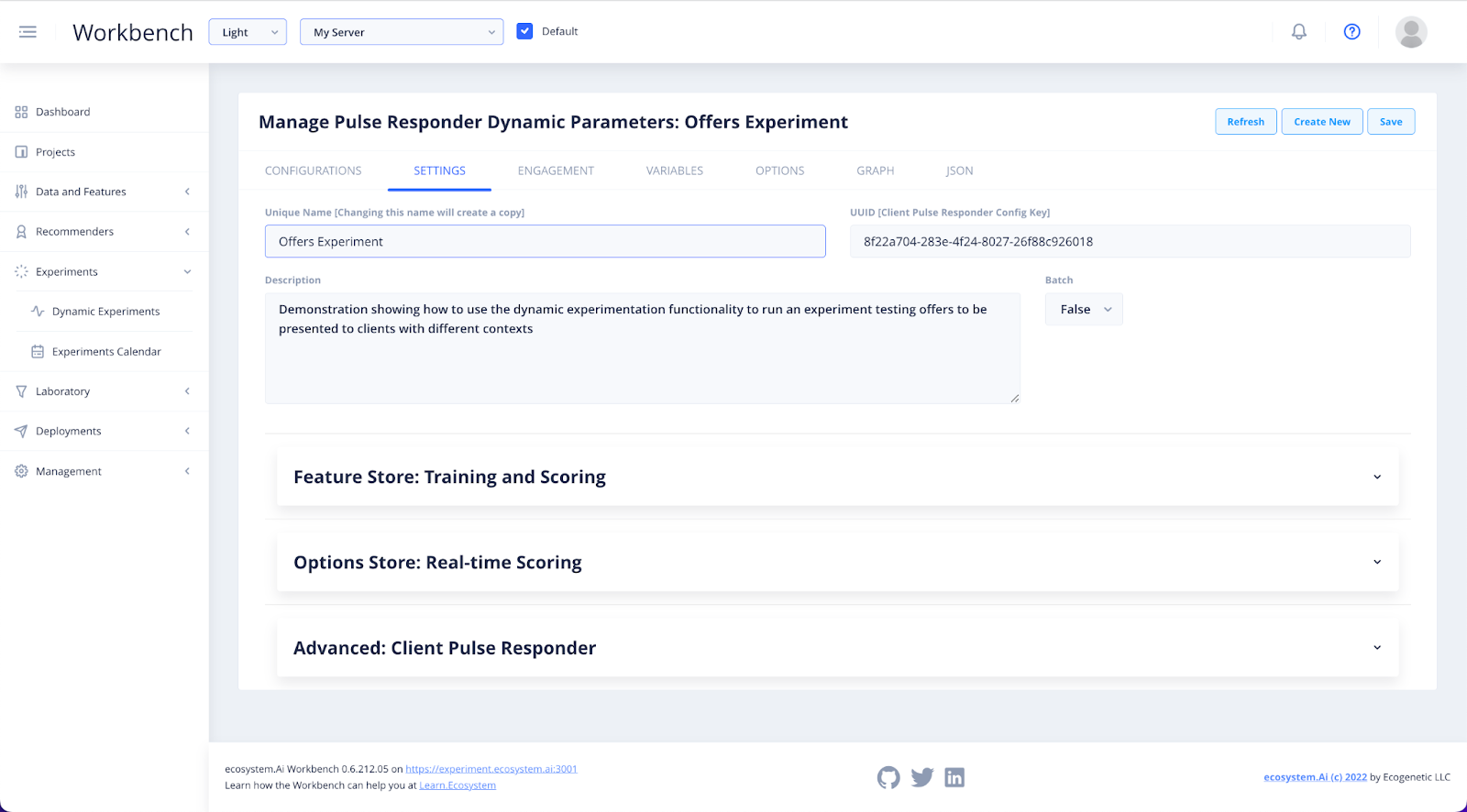
When you click into the experiment, you will notice a series of tabs along the top. These are your configuration tabs for that experiment.
To create a new Dynamic Experiment, select Create New.
In Settings is where you can view or create the Unique Name and Description of your experiment. The UUID field will be populated automatically when you click Save. This UUID will be used in Deployments.
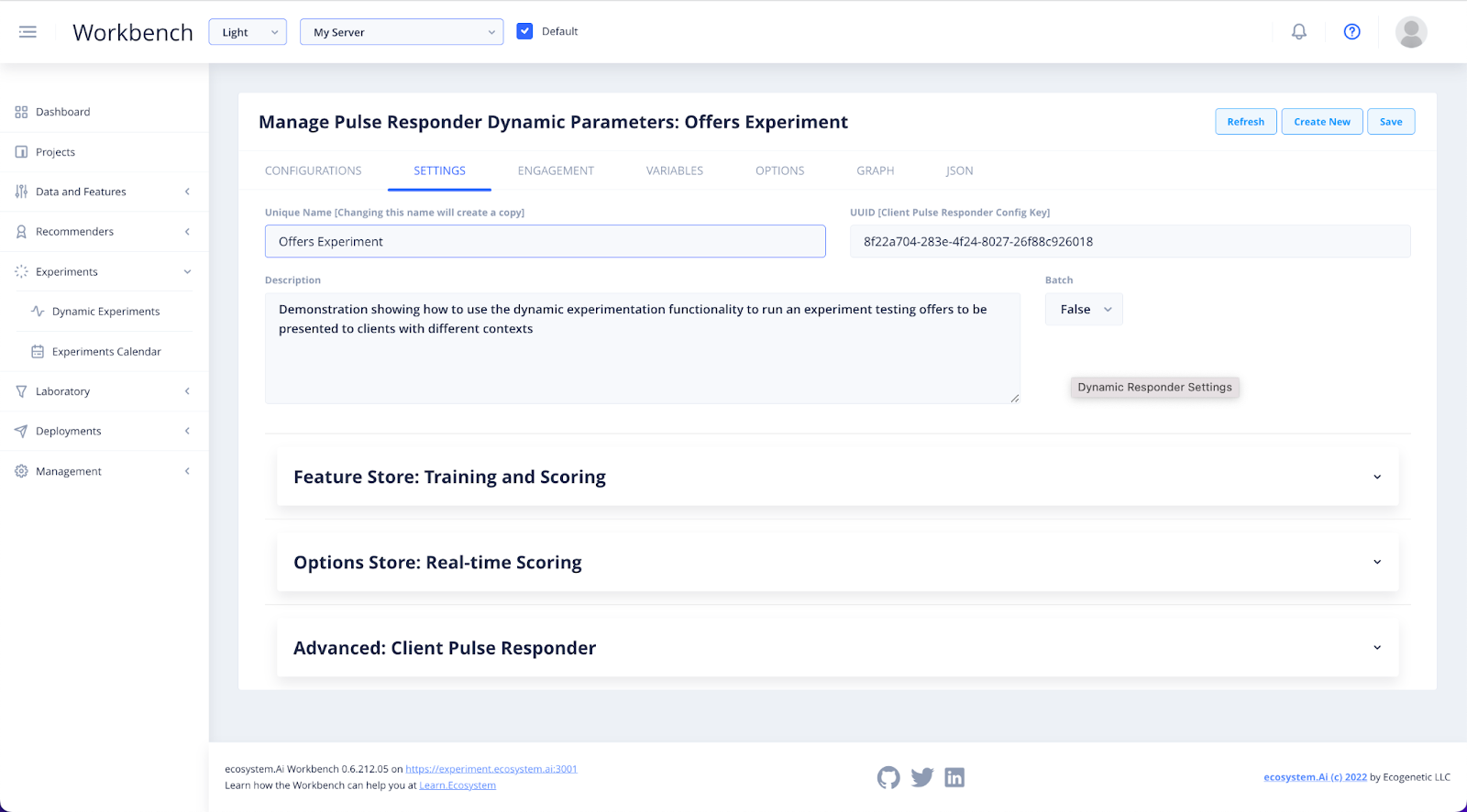
The Batch dropdown is where you can specify whether an experiment will be run in real-time or batch mode. When Batch is set to false, a real-time experiment will generate results for one customer interaction at a time. Feedback, in the form of an action, is fed into the system as soon as it is available. When Batch is set to True, it generates results for a number of customers at once. It does not incorporate feedback until the actions from those customers are loaded into the system at a later point.
When choosing between batch and real-time approaches it is useful to know that real-time is the more effective approach. However, your ability to run a real-time experiment may be impacted by technical constraints within an organization.
In the Feature Store: Training and Scoring dropdown you will be need to specify the location of the data you will use to set up your experiment.
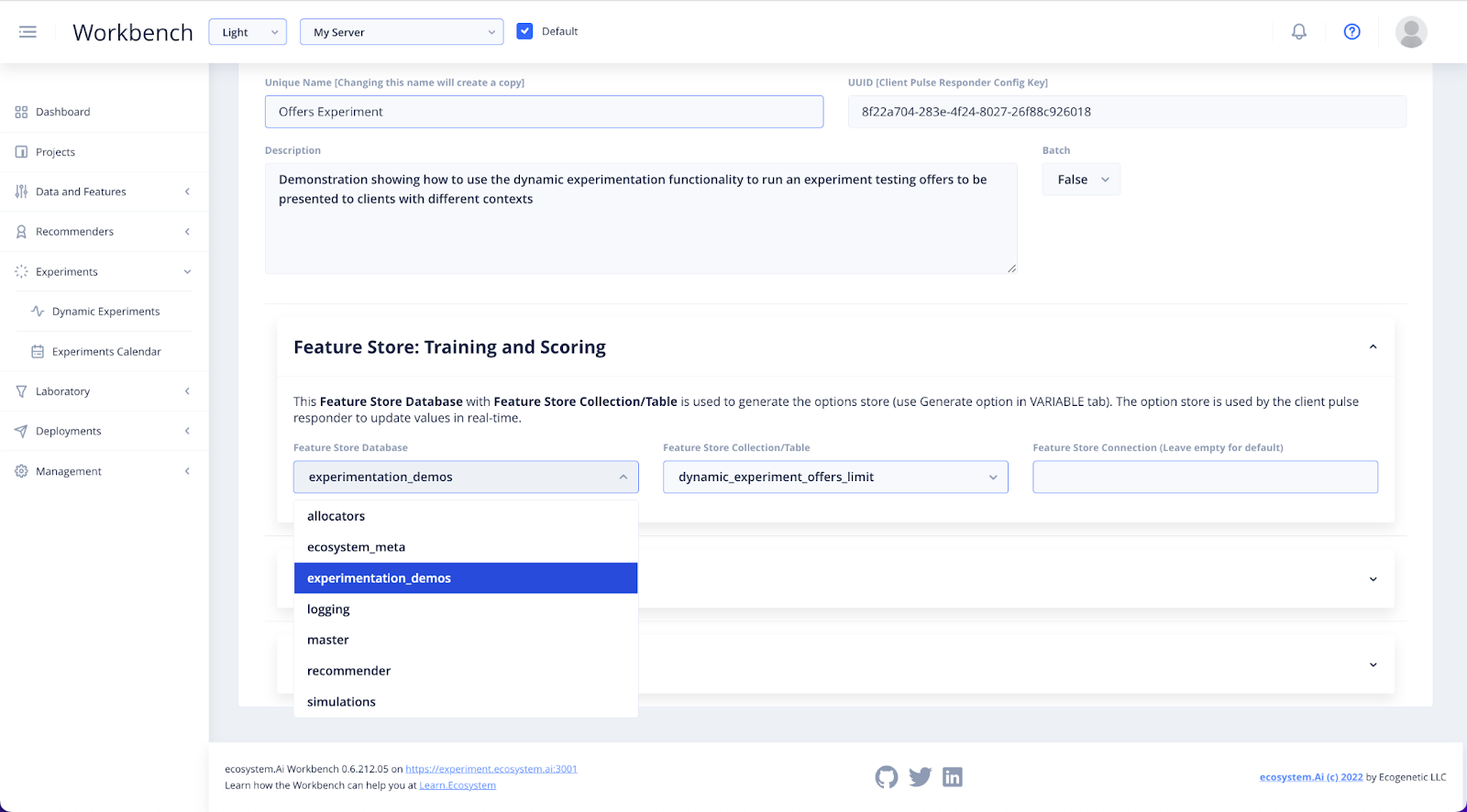
Use the Feature Store Database dropdown to find the database you created in Feature Engineering, and then allocate the Feature Store Collection. You can leave the Feature Store Connection empty if you are unsure about what to input here.
In the Options Store: Real-time Scoring dropdown you will specify the location where the options store will be created to.
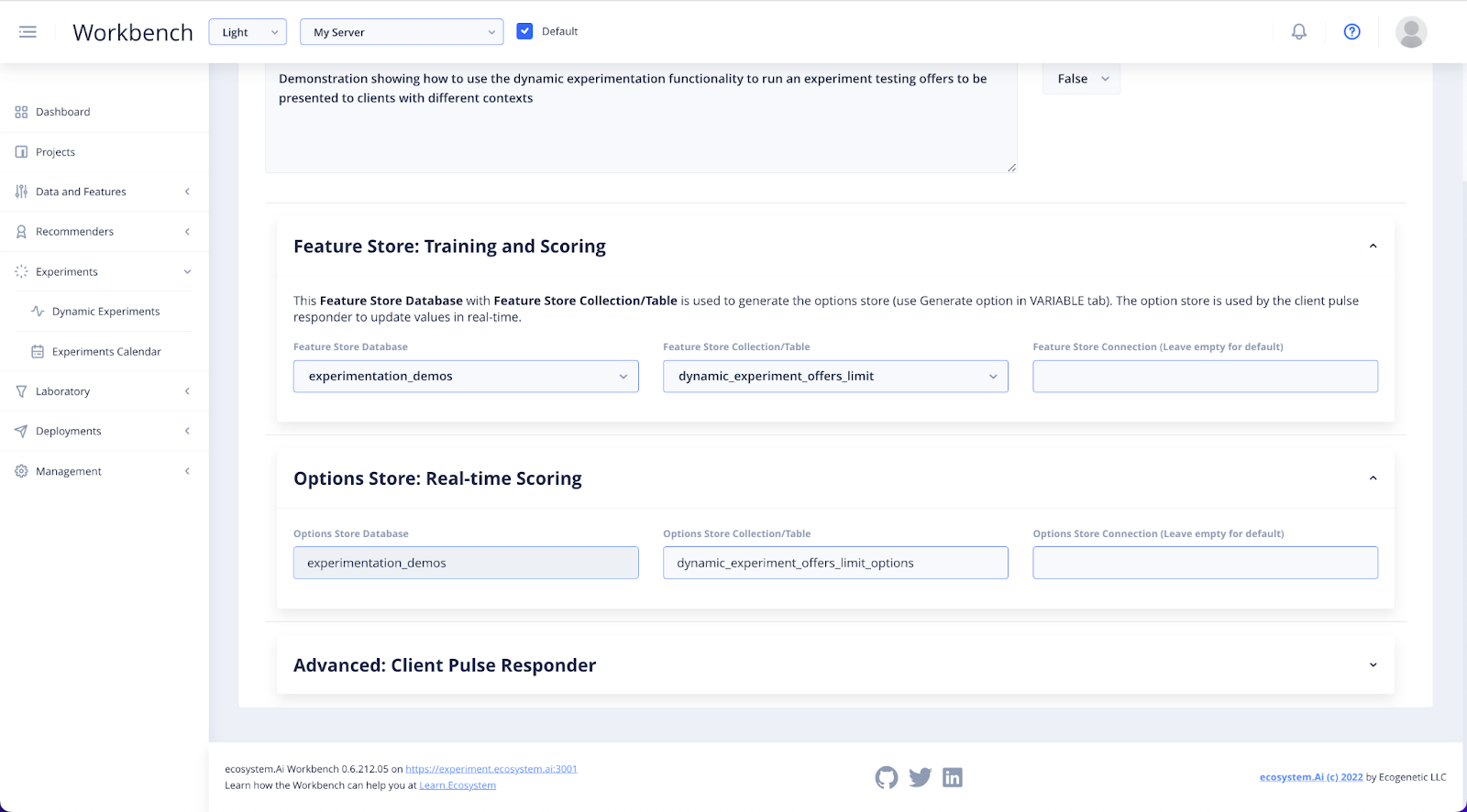
An options store is a list of experiment vidgets (offers), with information about the state of knowledge for each one.
You should not need to do anything in the Advanced: Client Pulse Responder dropdown.
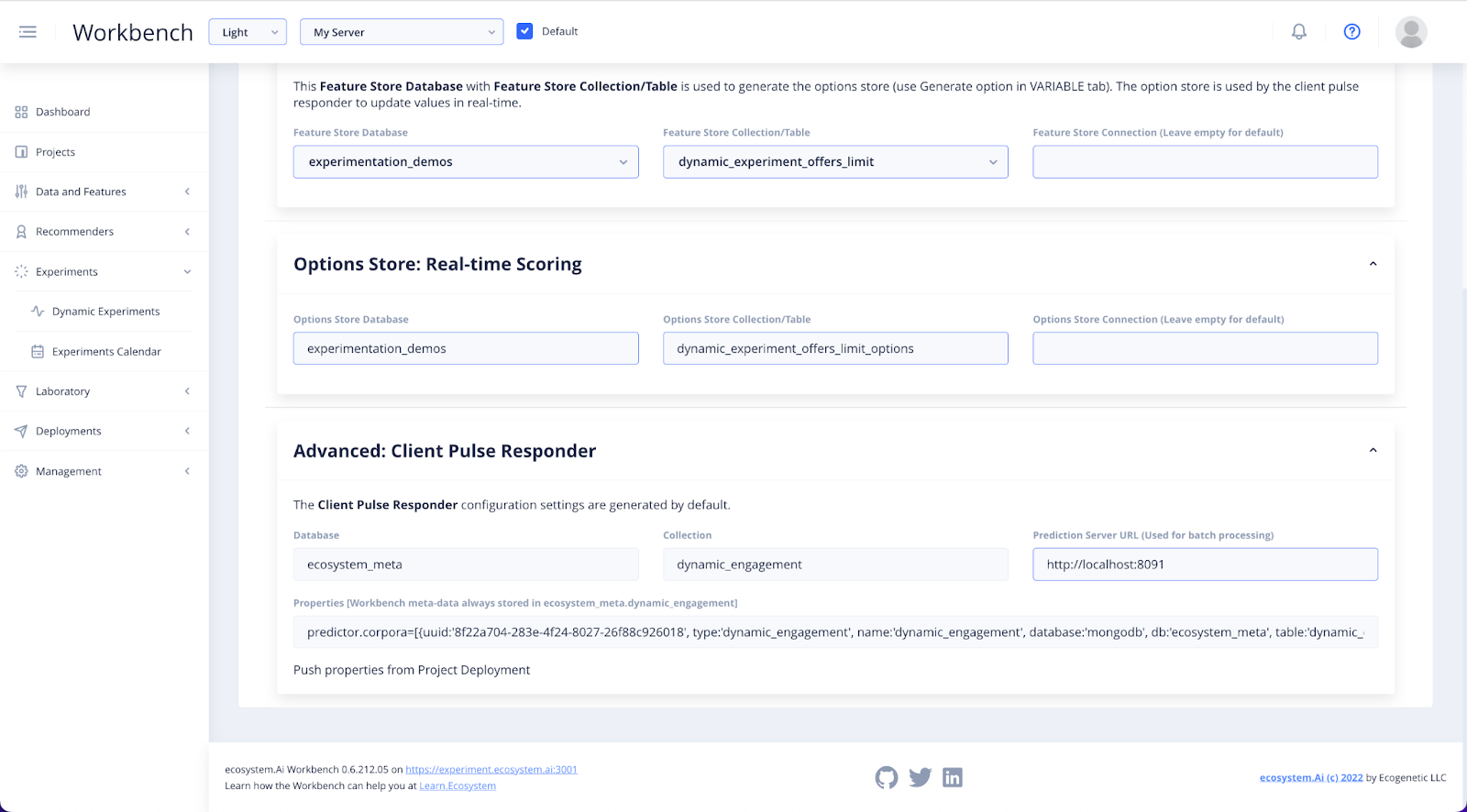
You can, if you want, click on the Properties file that has been populated to double check whether it has been successfully linked. But this is not essential.
Save your Settings before continuing to Engagement.

Add and configure your Experiment Engagement and Variables
In Engagement you will be prompted through a series of configuration steps by the Setup Wizard.
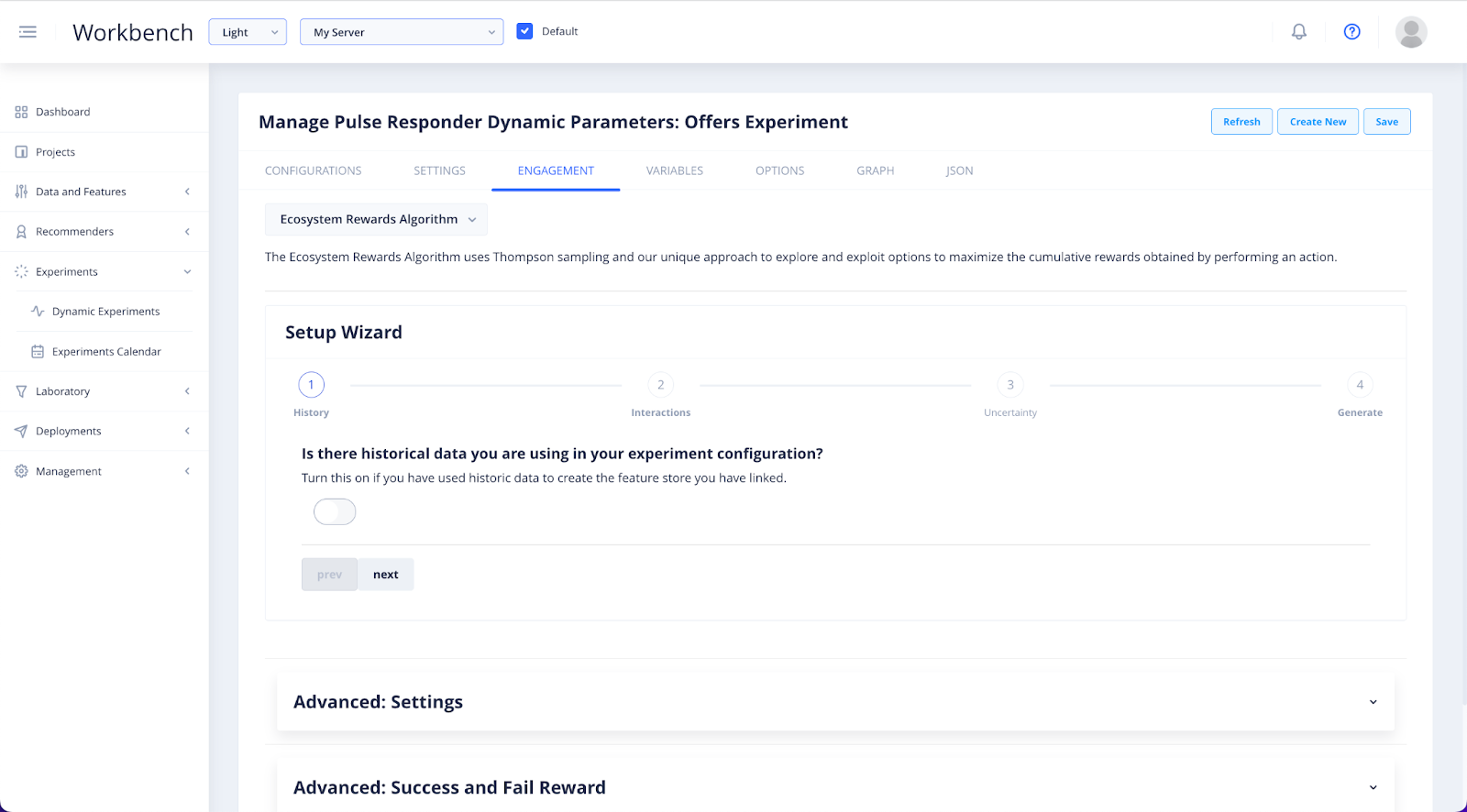
Before going through the wizard, you will need to select which experiment algorithm you wish to use. If you are unsure of which to choose, select the Ecosystem Rewards Algorithm.

Once you have chosen your Algorithm, Save your progress before continuing to the Wizard steps.

In the History step, you will need to use the toggle to specify whether you have decided to use historical data in your Experiment.
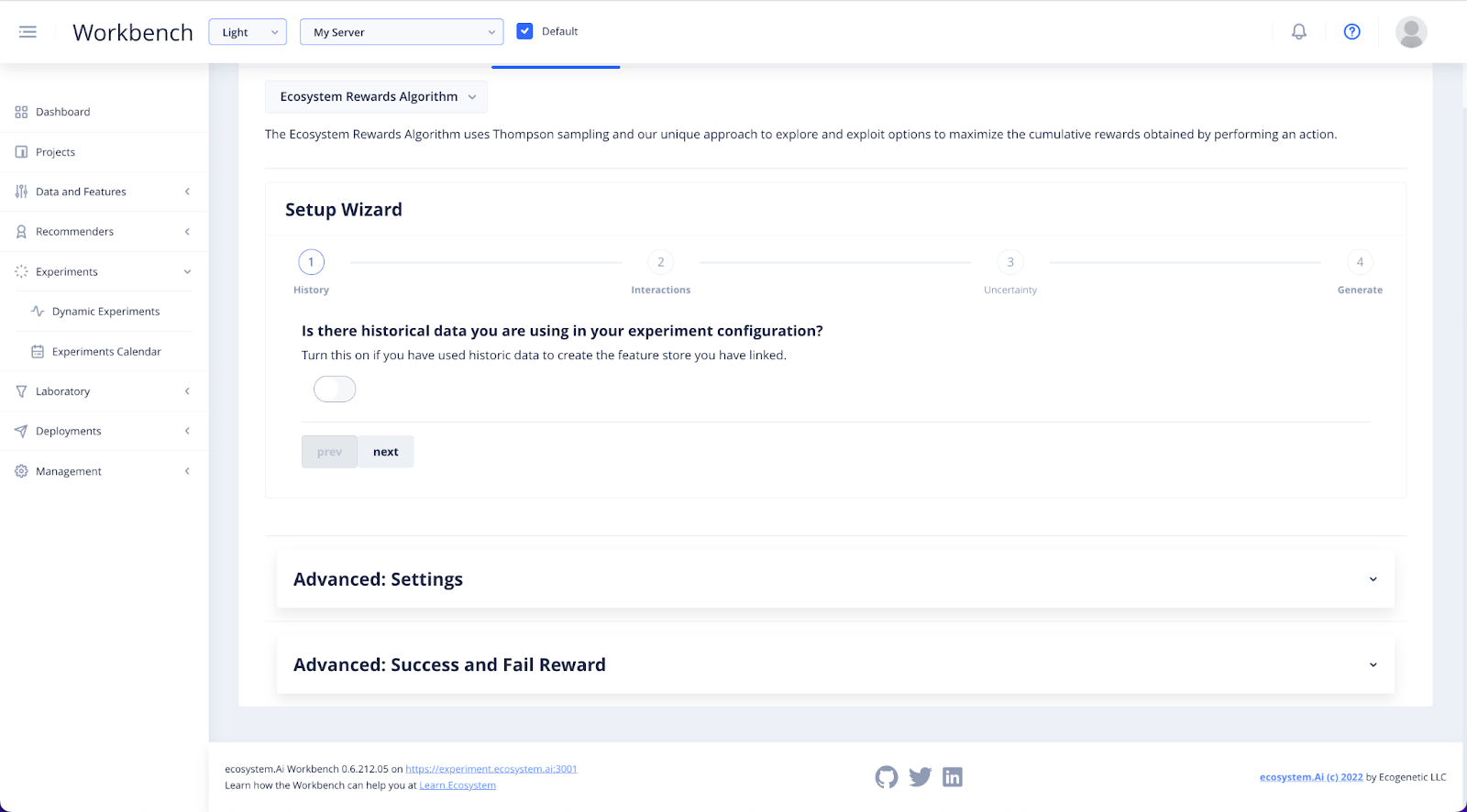
If you are following our prompts to set up a test without data, click Next.
In the Interactions step, you will need to provide some educated guesses reagrding the expected rate of interaction and vidget take-up of your offer.
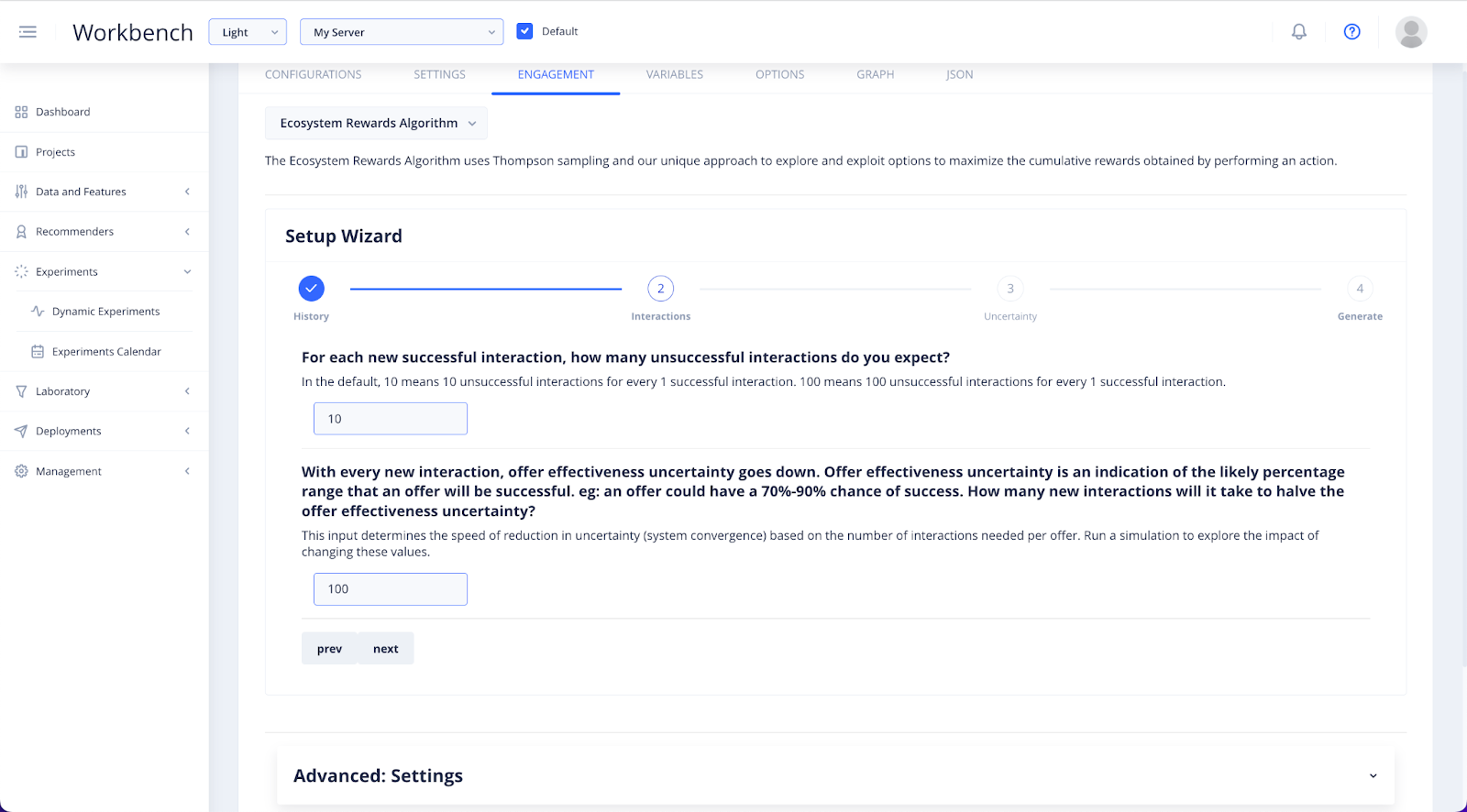
The configurations you set in this part of the process are not set in stone. You can use these values to run simulations to explore the impact of your settings.
Next, you will need to set up your Uncertainty parameters.
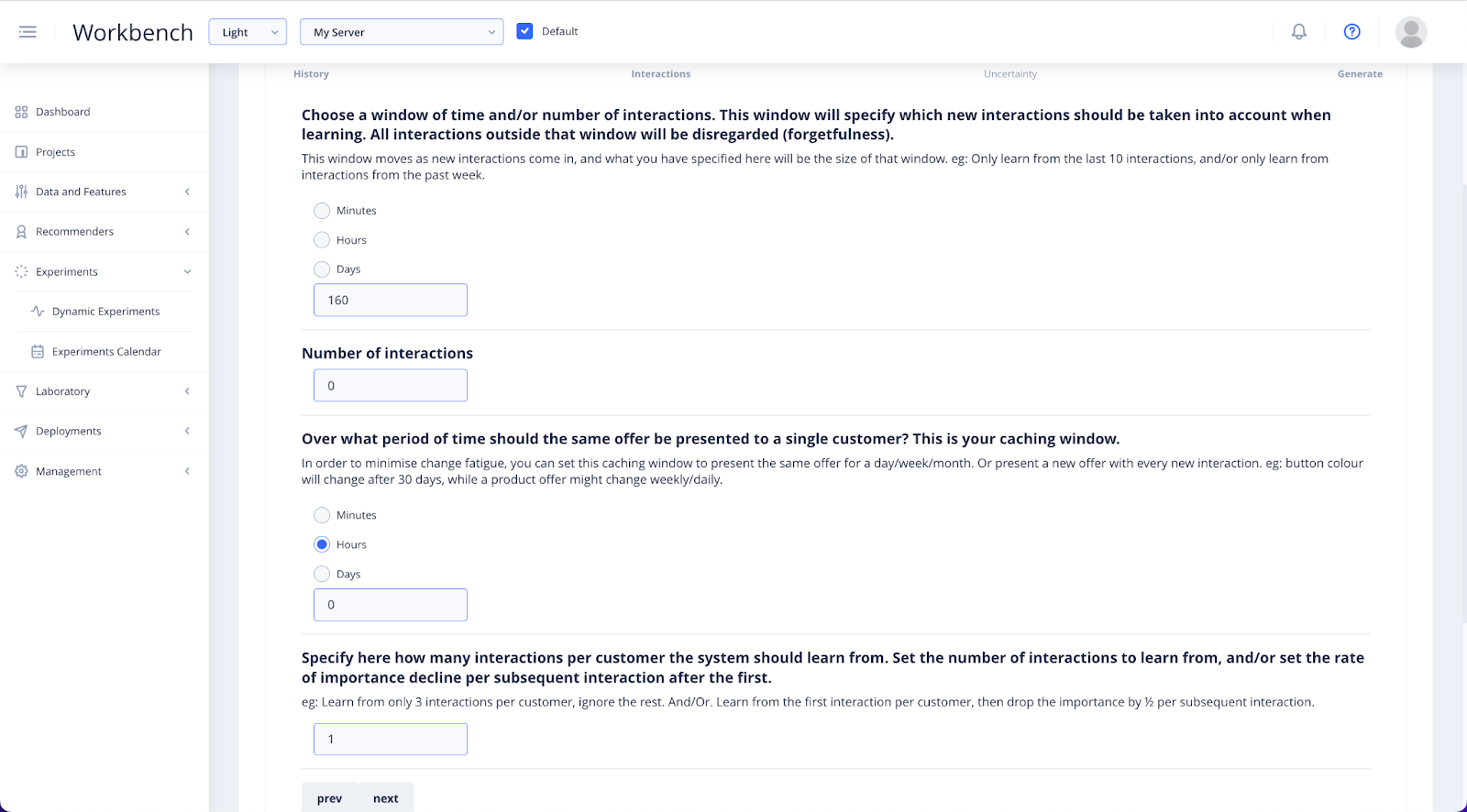
Here you will set the learning windows of forgetfulness, the caching period of showing specific offers, and specifying the learning of interaction importance.
In the last step, you will generate the Engagement configuration.
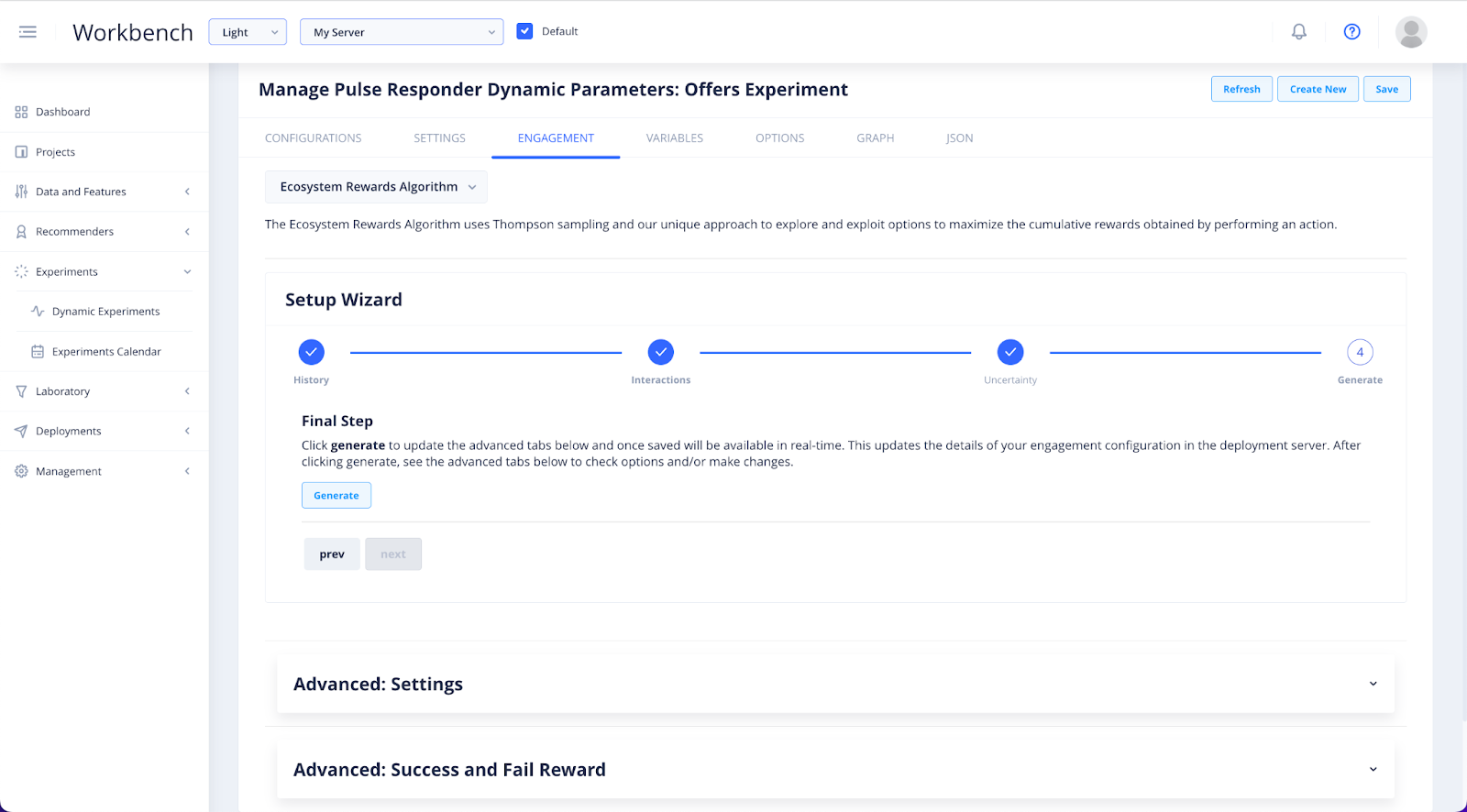
Click Generate to populate the advanced dropdowns with these settings, Save and then go to Variables. To learn more about the Advanced: Settings see the PDF attached to the end of this lesson https://ecosystem.ai/docs/solve-your-data-access-and-resource-capacity-constraints/#9-toc-title
In Variables you will specify the data that will be used in your experiment configuration options store setup.
In these fields, you will be able to extract and view the details of your vidget features (keys). Here you will need to specify the details (if any) on user context, such as demographic, behavioral, etc. and historical behavior.
Click on the Key List field to automatically return a list of keys in your data.
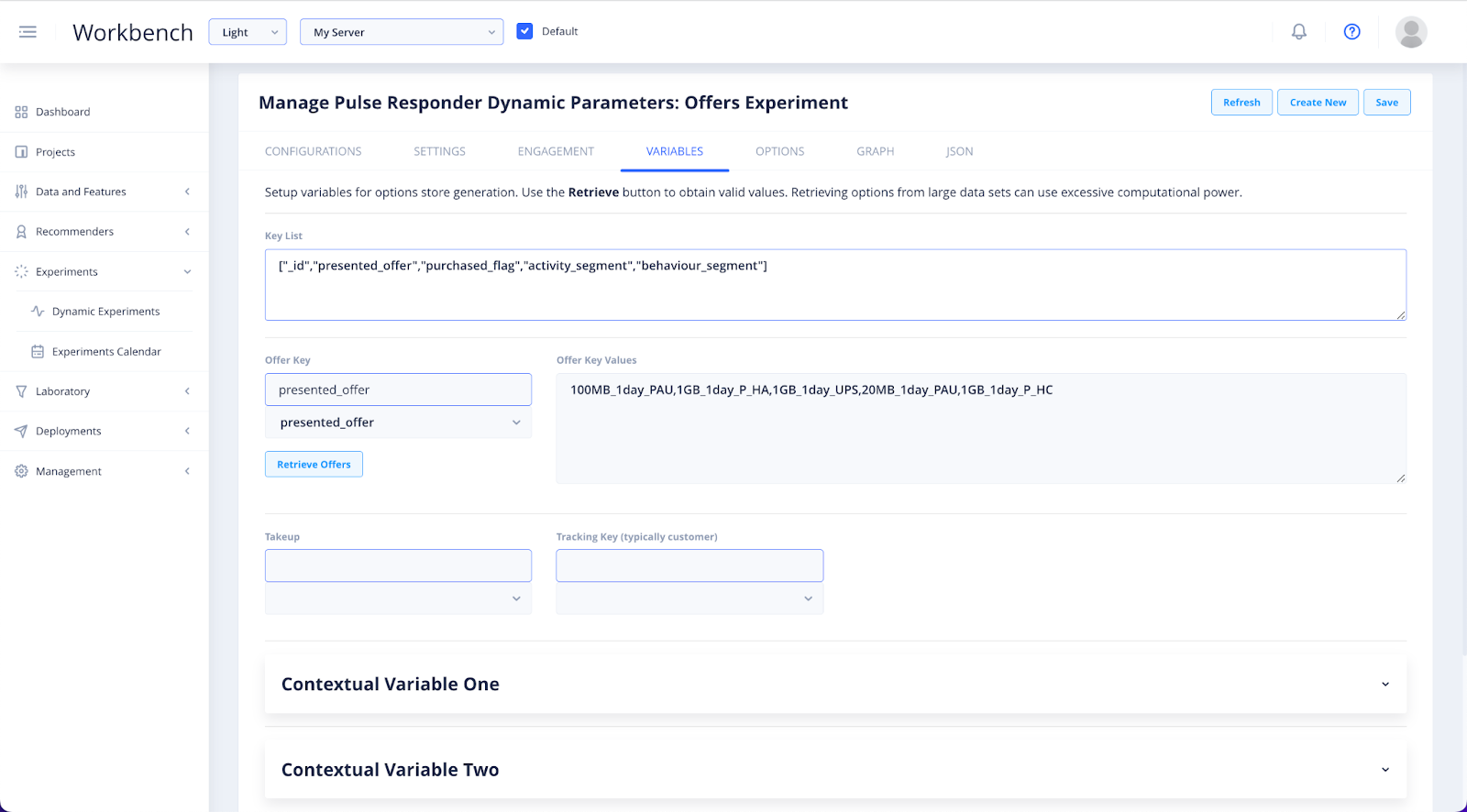
Then use the Offer Key dropdown to select the key you wish to use and Retrieve Offers to bring back a list of the Offer Key Values.
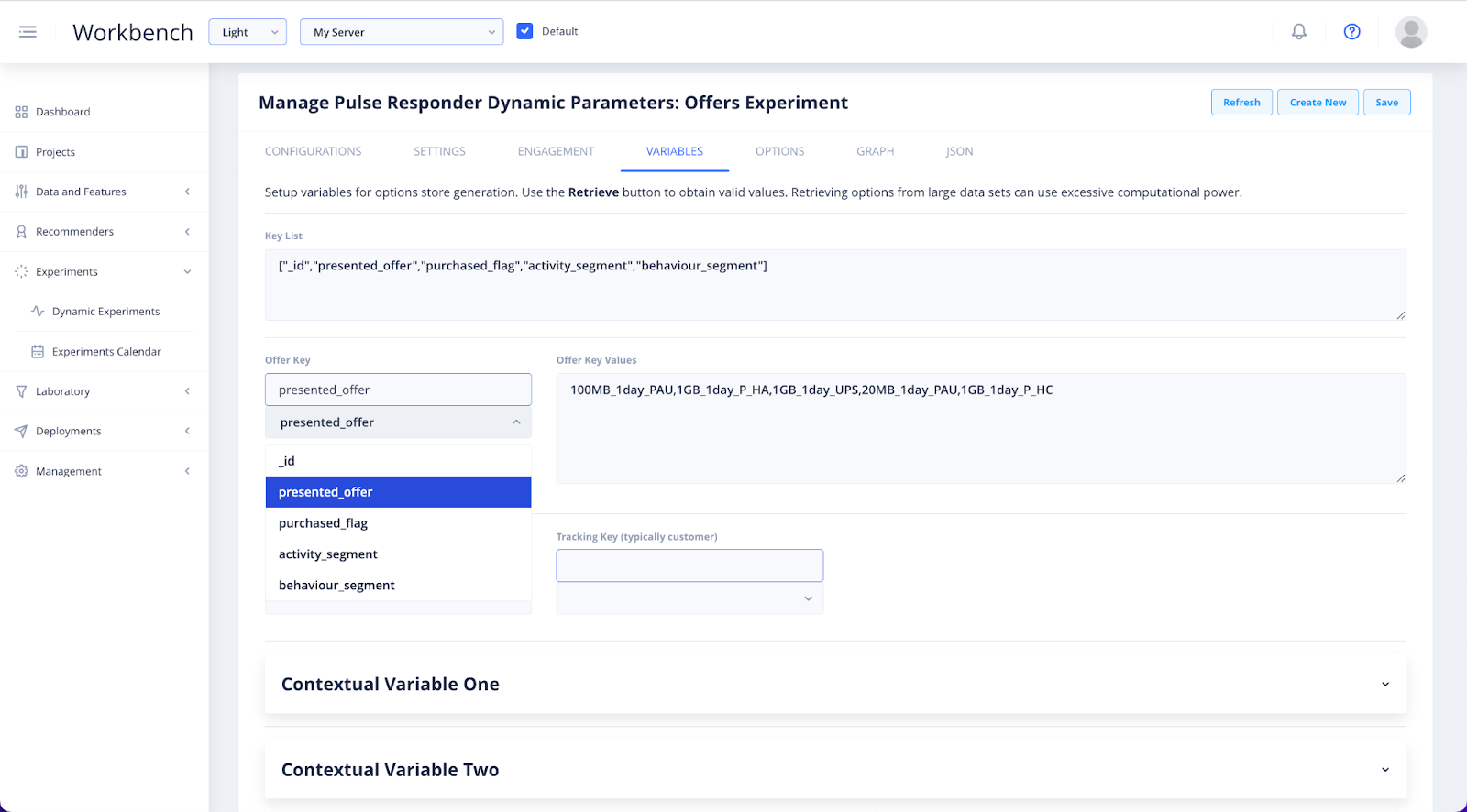
The only required input is Offer Key. This is where you will specify the name of the vidgets to be ranked in your data set. In addition to the Offer Key you can add a Takeup Field.
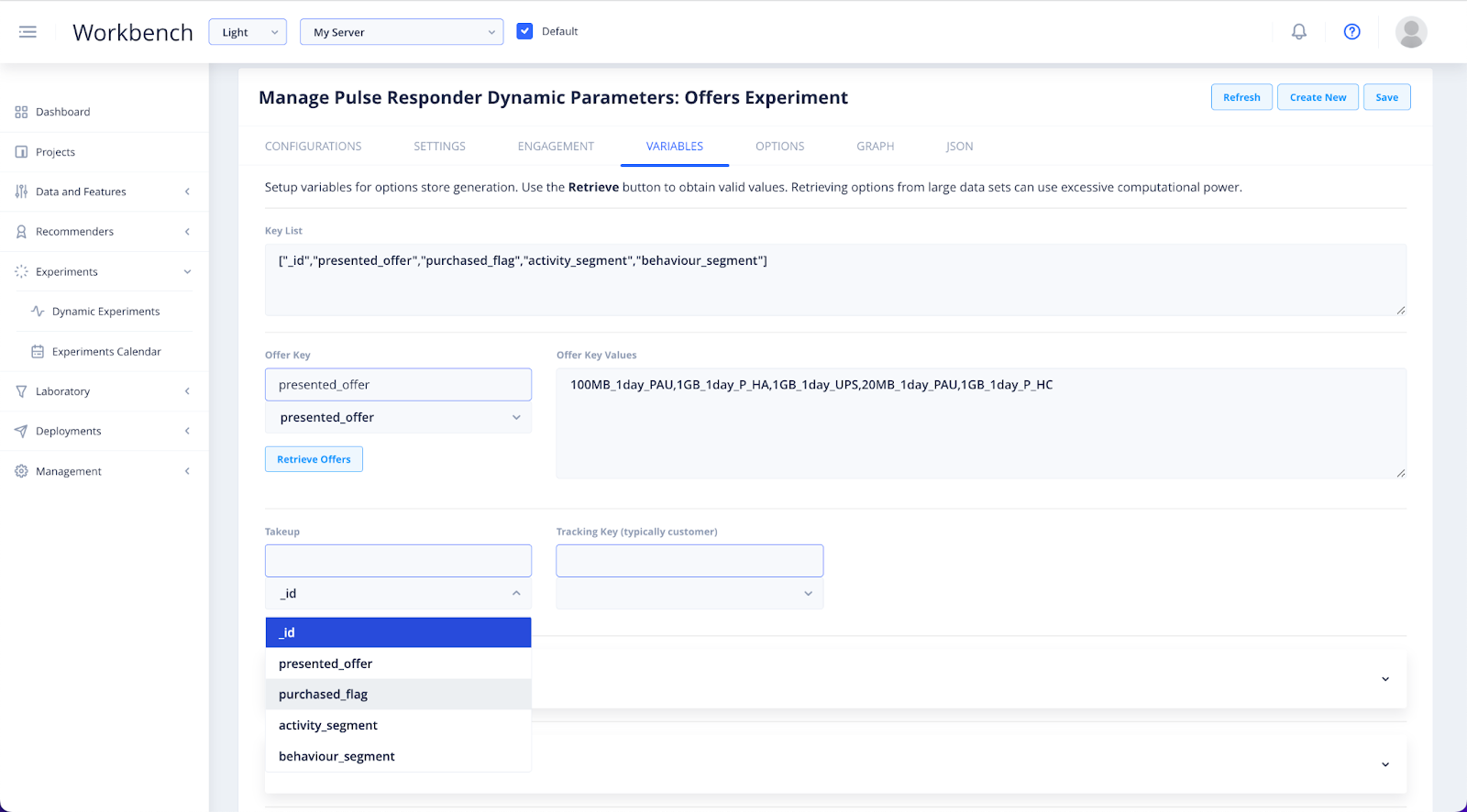
You will only specify the details here, if your data includes historical behavior. A tracking key can be added if you want to track behavior and learn at an individual customer level. This will only be used if there are regular repeated engagements with individual customers.
In the Contextual Variable One and Contextual Variable Two dropdowns, you will specify the data on user context.
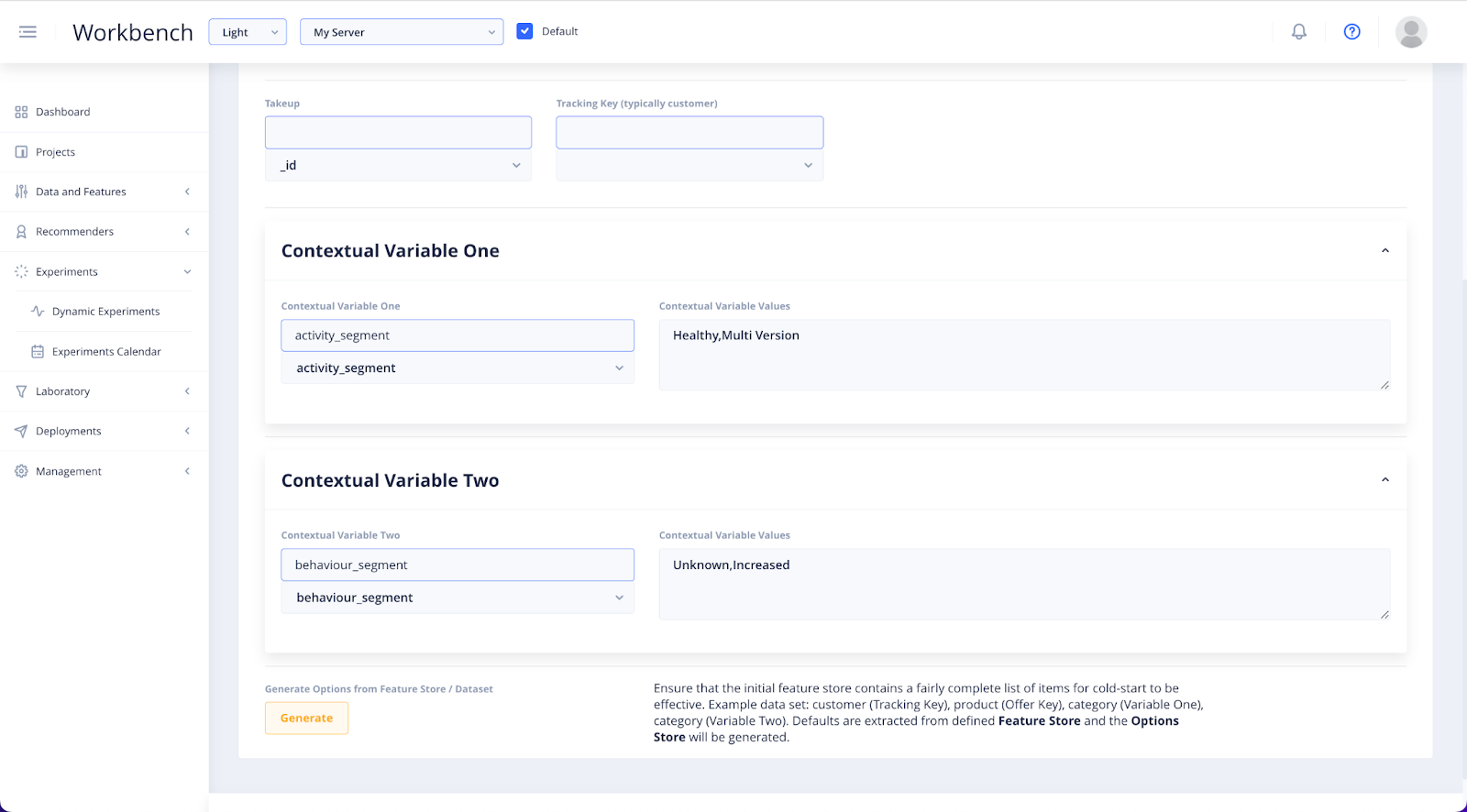
Contextual Variables allow you to set other layers of context for your offers. If you have segments in your data which interactions can be tracked and learned from, you will specify them here. For example, you can produce different rankings for different segments of people you want to display vidgets to.
Once all of the Variables have been set, click Generate to create, store and display the Options Store.

When you click Generate you will be redirected to Options which is where you will find the Options Store.
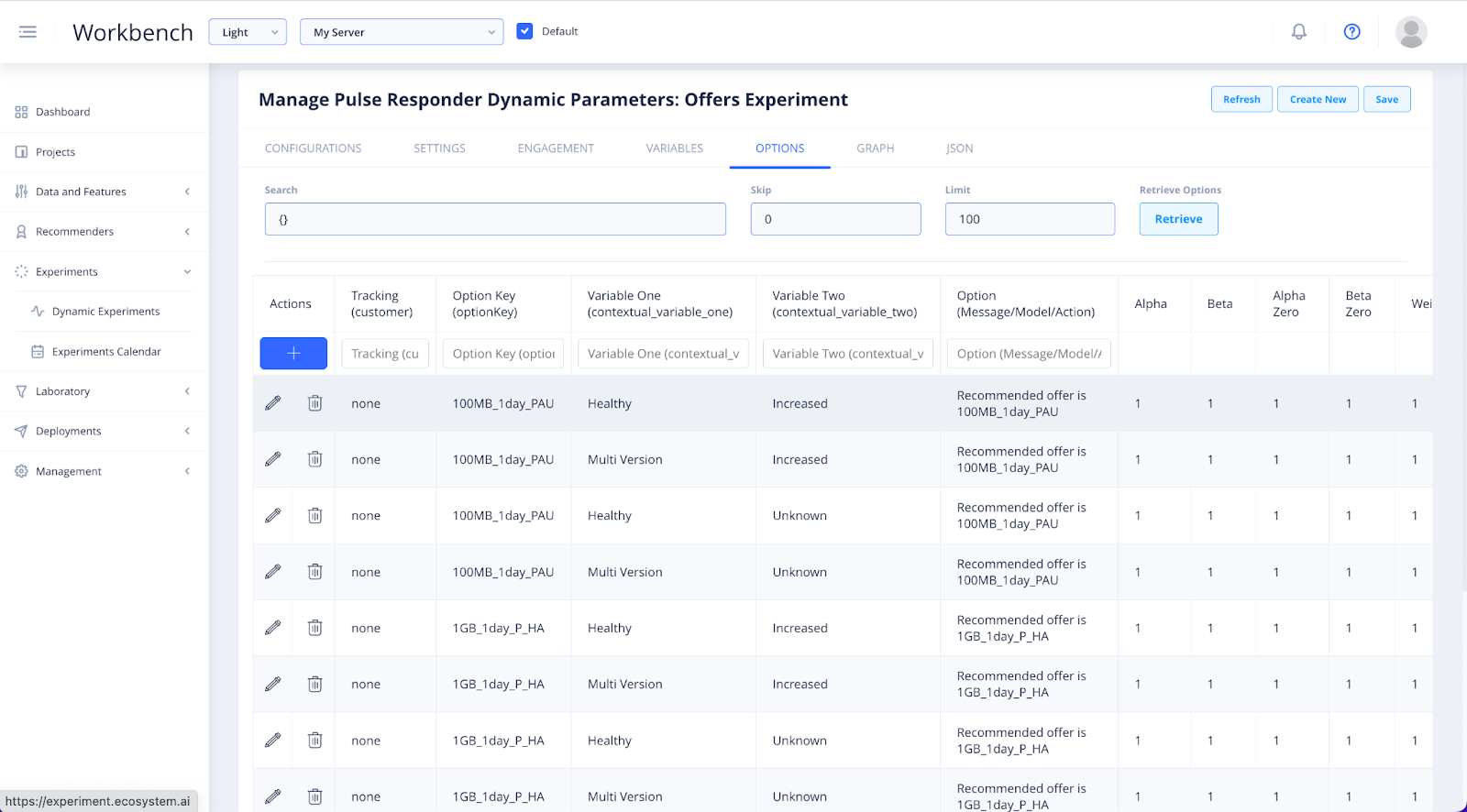
In the Options Store, you will be able to track the activity of your experiment as it ranks the offers and takeup in production, based on customer feedback.
Add and configure your Experiment Graph and JSON
In Graph you will be able to view a graphical depiction of your options store set up.
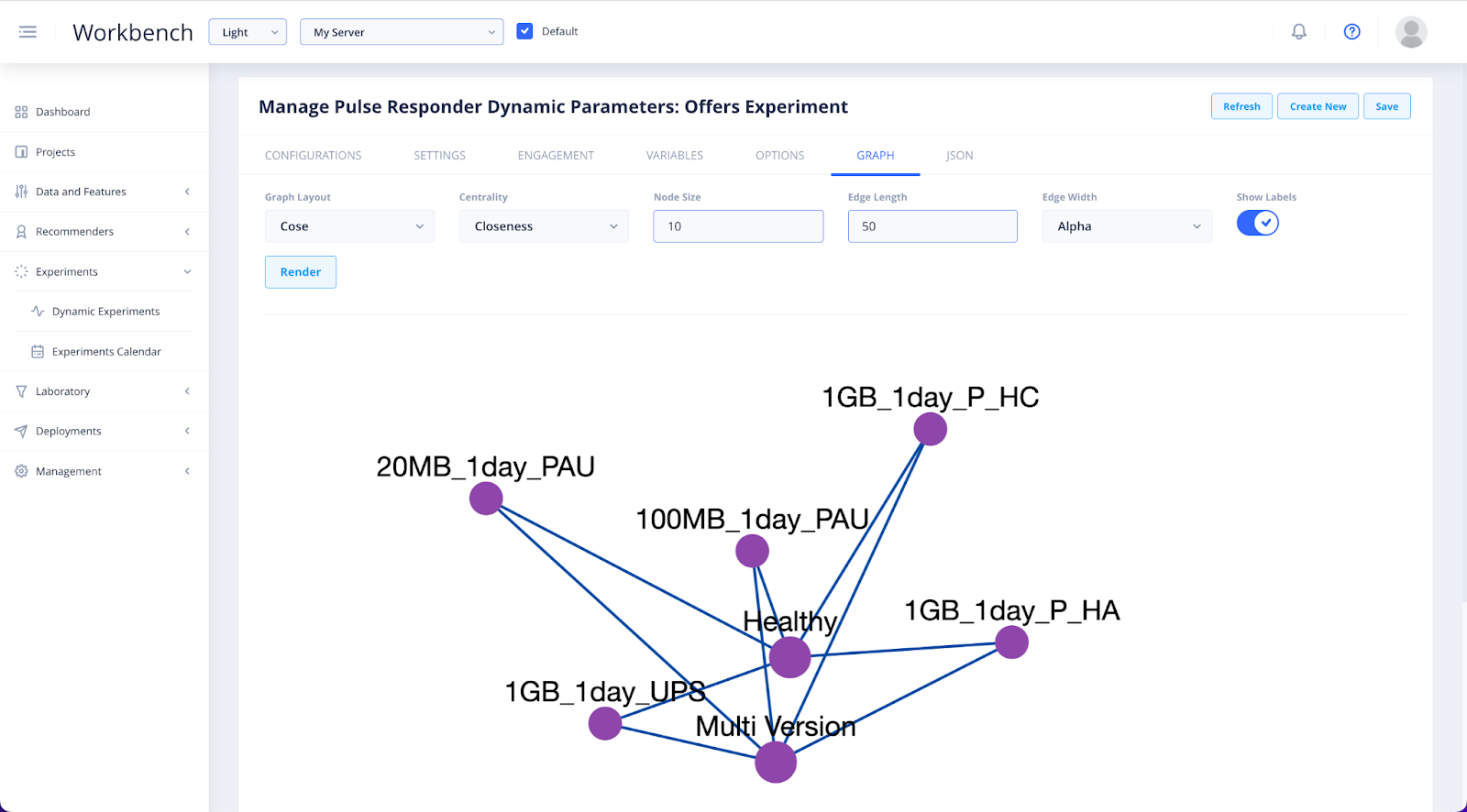
Use the various dropdowns to set the graph variables, in order to view factors such as Closeness, Cose, and more.
In JSON you will be able to view your experiment configuration as stored in the platform metadata.
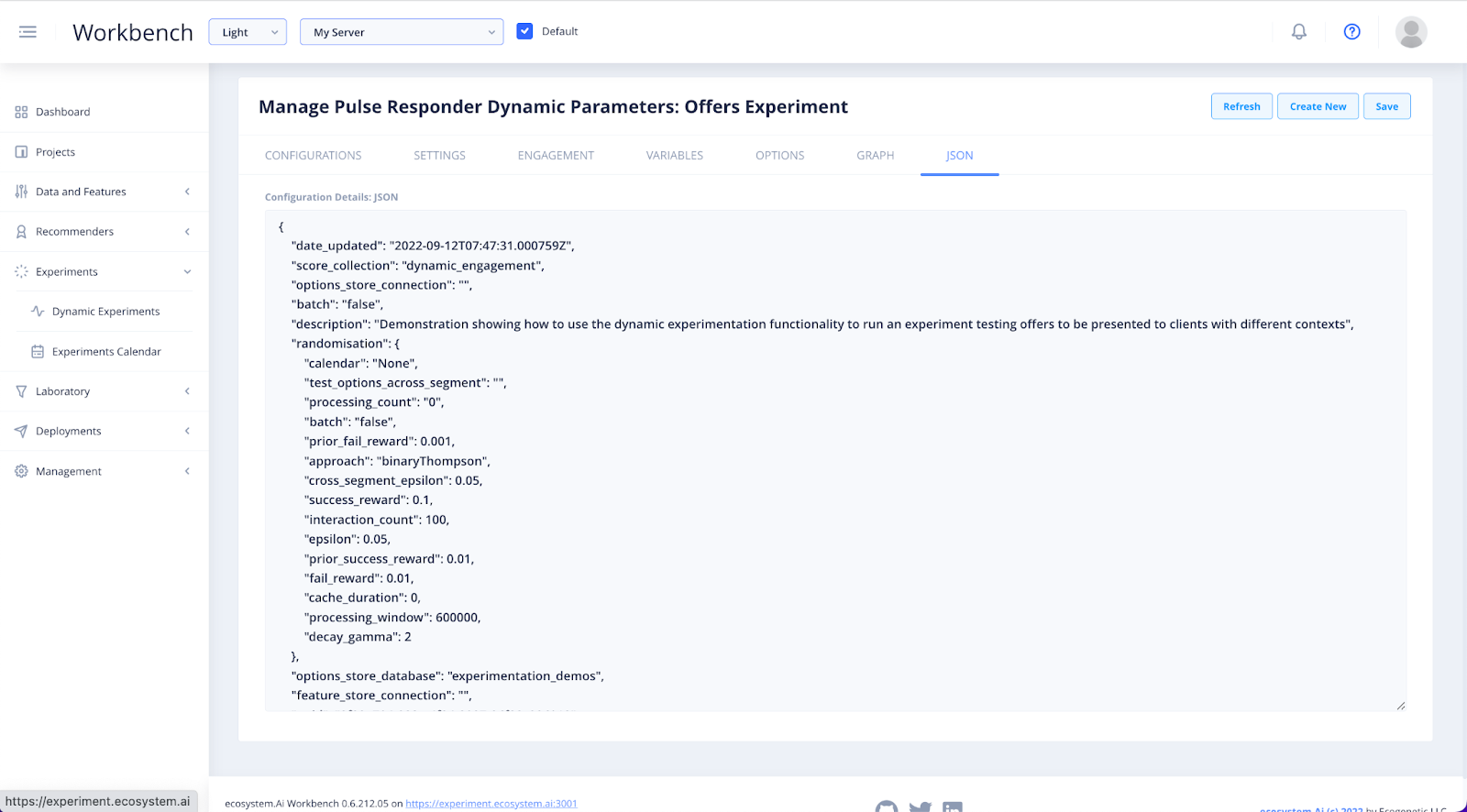
Once your experiment has been created and all the configurations set, be sure to Save before heading back to the Configuration tab.
Take note of the UUID associated with your configuration.
Now that your Dynamic Experiment is set up, it is time to configure your Deployment details.

Deployment #
Now that you have uploaded, ingested and viewed your data and configured your dynamic experiment, you will need to put your experiment into production. Deployment is where you will set your experiment to be used in the Production, Quality Assurance or Test environment.
In the Deployment section of the Workbench, you will find Projects.
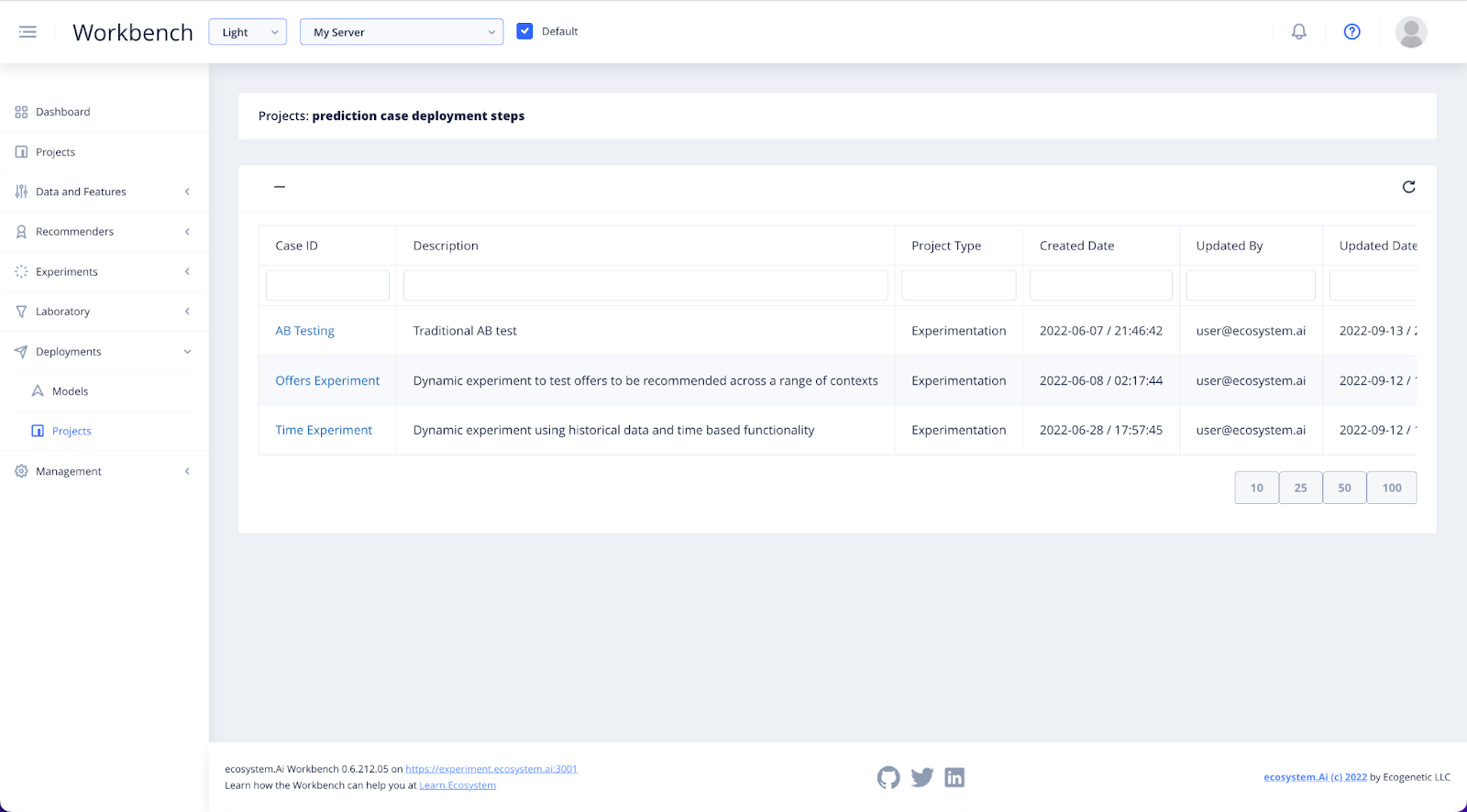
This is where you will be able to configure the parameters of your deployment, and push it to the desired environment.
note: MOST SETTINGS IN THIS TAB CAN BE LEFT WITH THEIR DEFAULT VALUES.
Find your project in the list of projects and click on it to view or create the deployments for it.
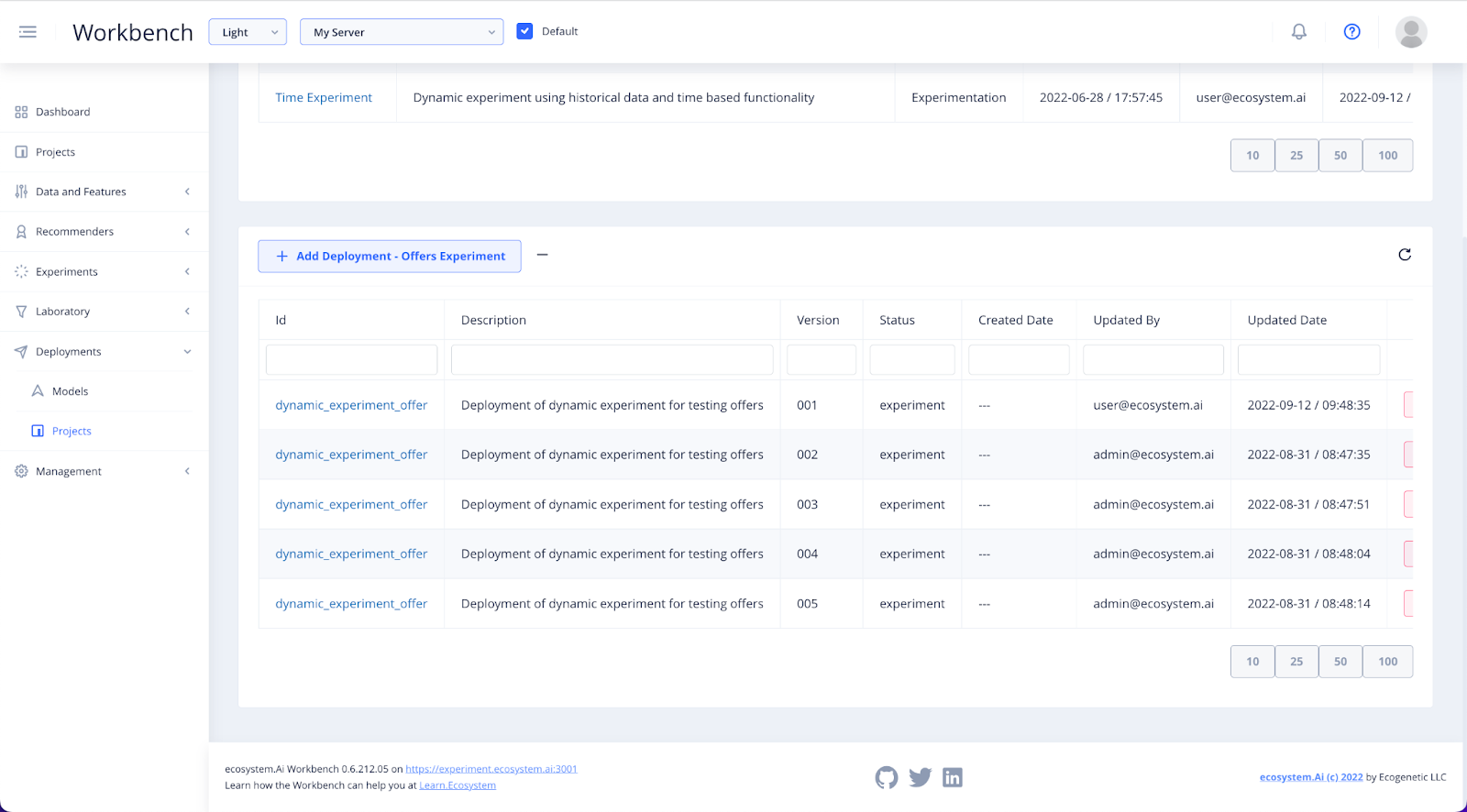
To view and edit a pre-existing deployment configuration, click on the deployment name. In order to create a new deployment, select + Add Deployment.
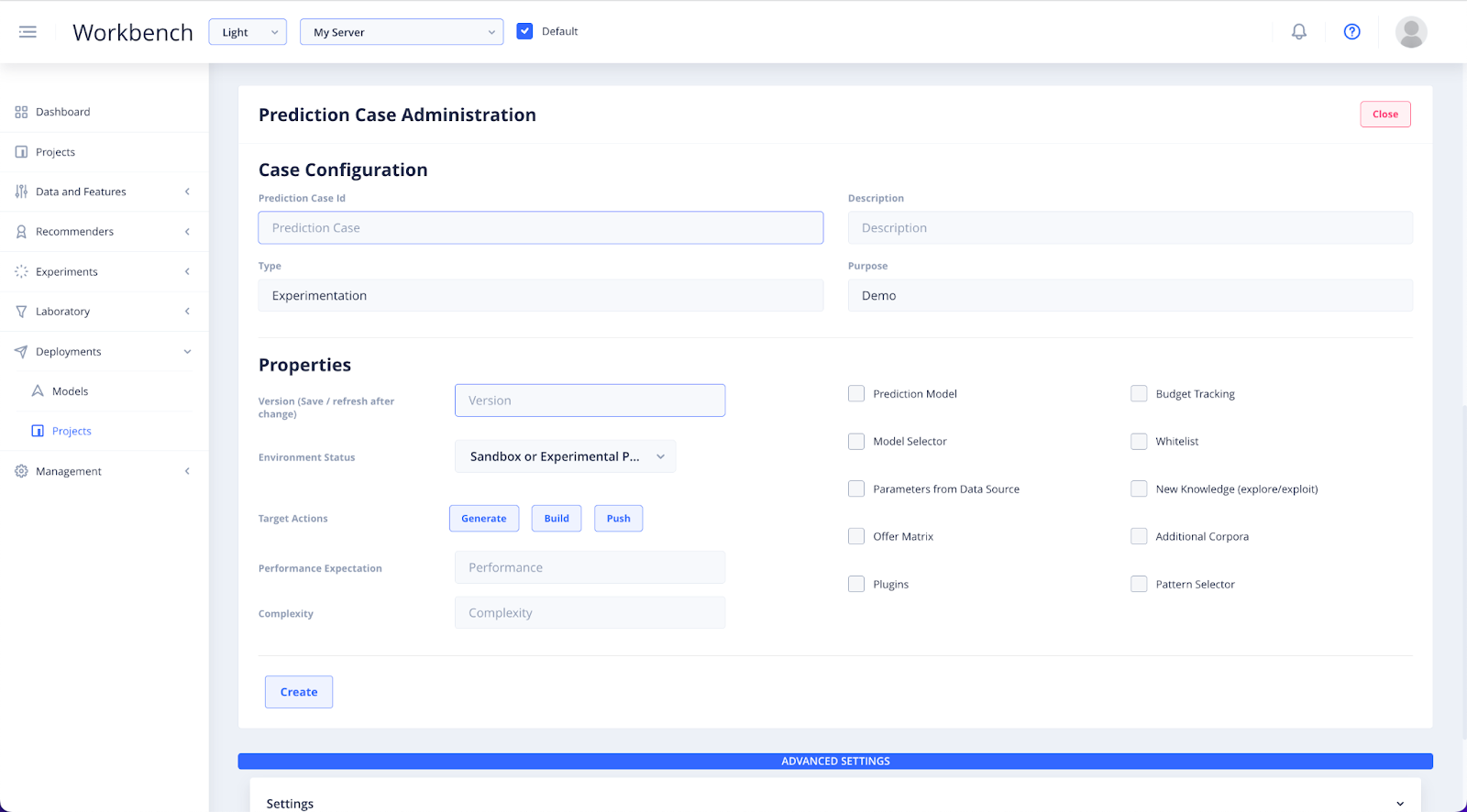
A window will open up below where you can specify the details of your new deployment.
Set the case configuration for your recommender deployment.

Create a unique Prediction Case ID name. Add a Description that is relevant to the specific deployment you are configuring. Add the Type and the Purpose of your deployment. You can leave the type and purpose blank if you are unsure of what to put there.
Then input the properties details and set the Version of the deployment step.
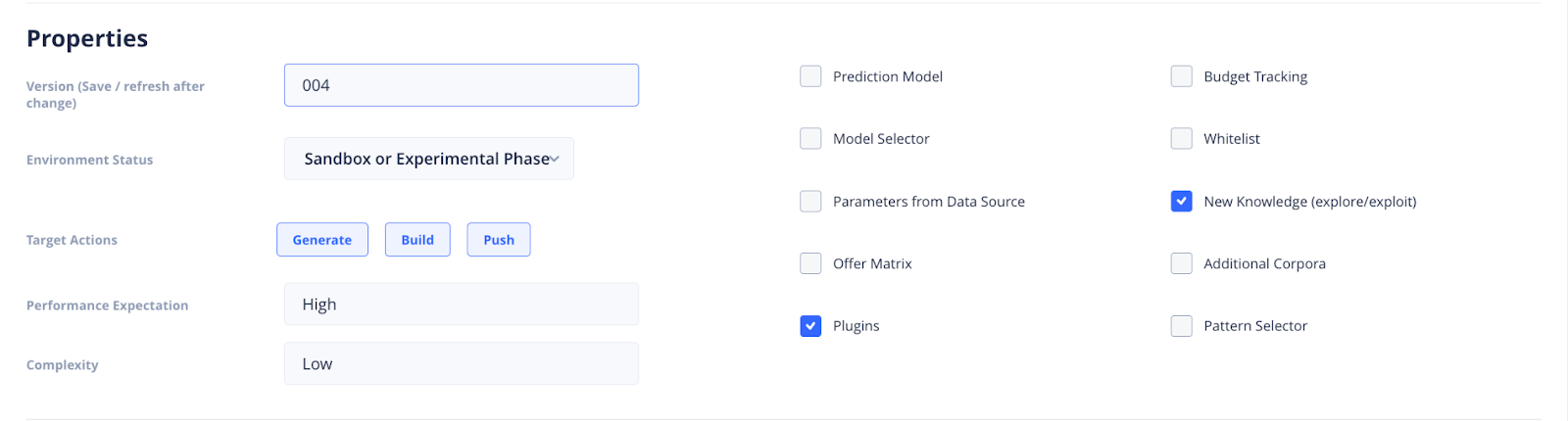
This Version number should be updated every time you make changes to the deployment. Specify the Environment Status in which you will be deploying your configuration. Then input the Performance Expectation and Complexity settings for your set up.

Update your Deployment before filling in the details in the settings dropdown. Selecting any of the Prediction Activator checkboxes on the right, will reveal Settings sections relevant to that option, at the bottom of the page.
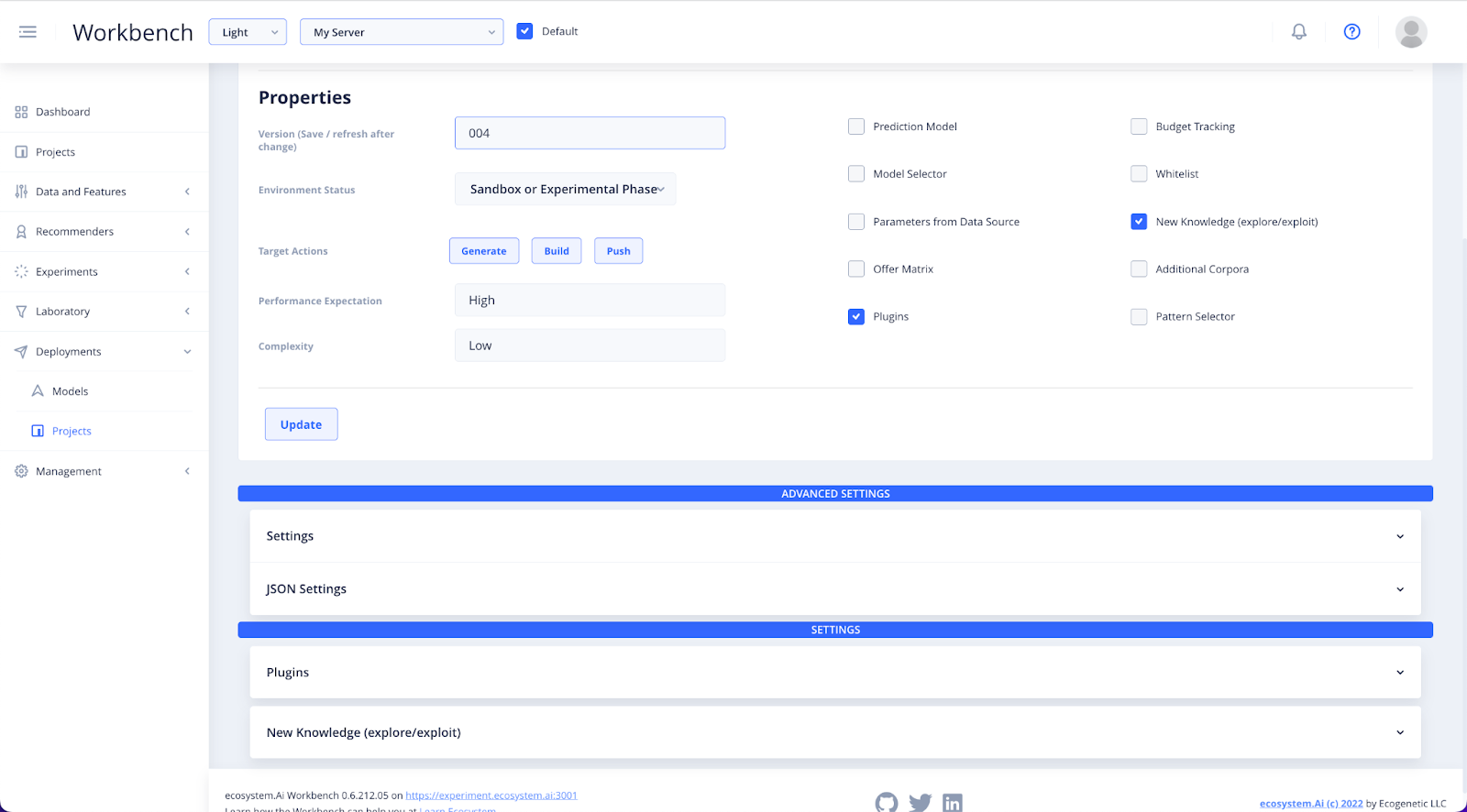
Select Plugins to use the pre-defined scoring class in your experiment.
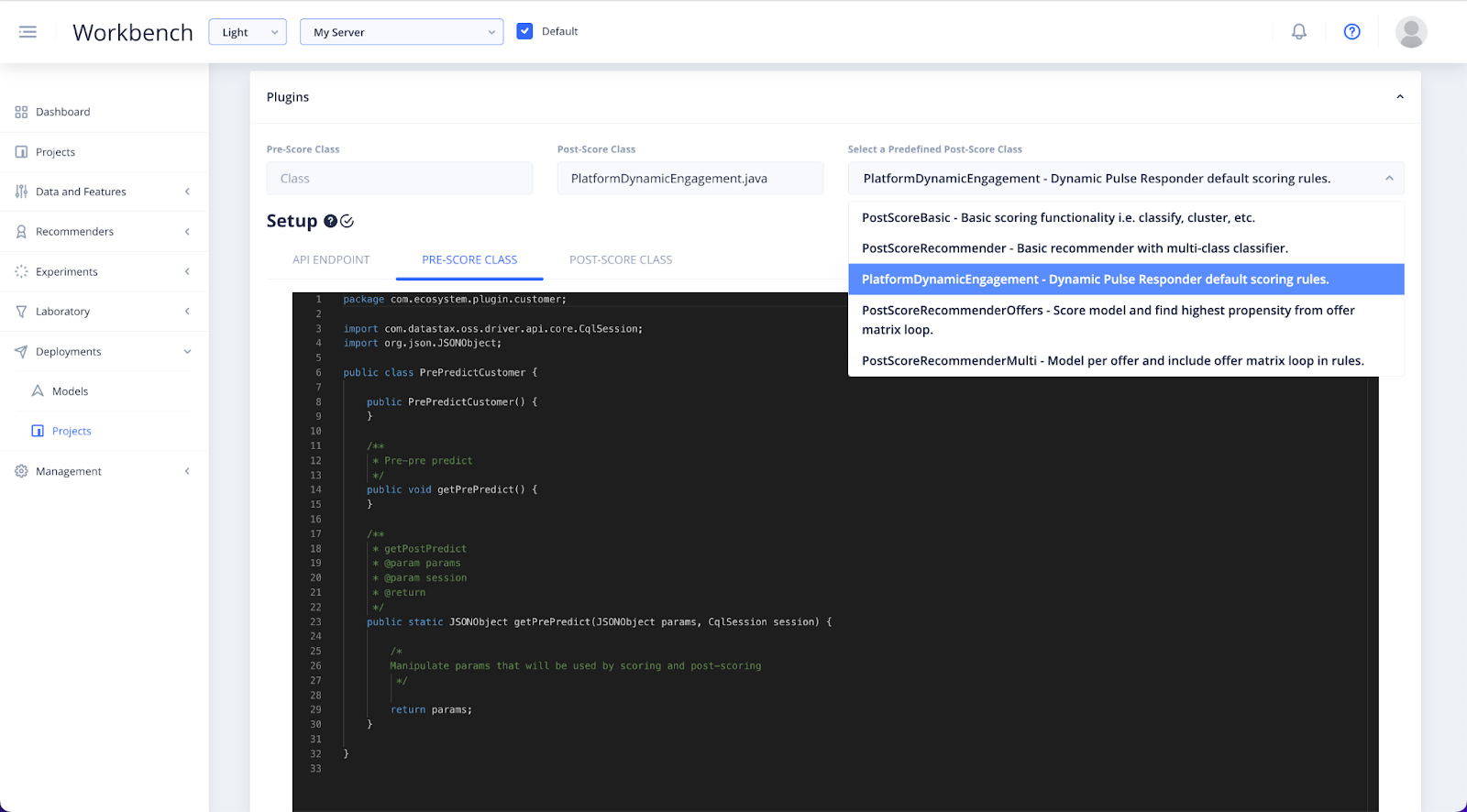
Use the dropdown to Select a Predefined Post-score Class and choose PlatformDynamicEngagement. You will see that this selection will populate the Pre-score and post-score class windows.
Select New Knowledge(explore/exploit) to assign the UUID you generated in Dynamic Experiments.
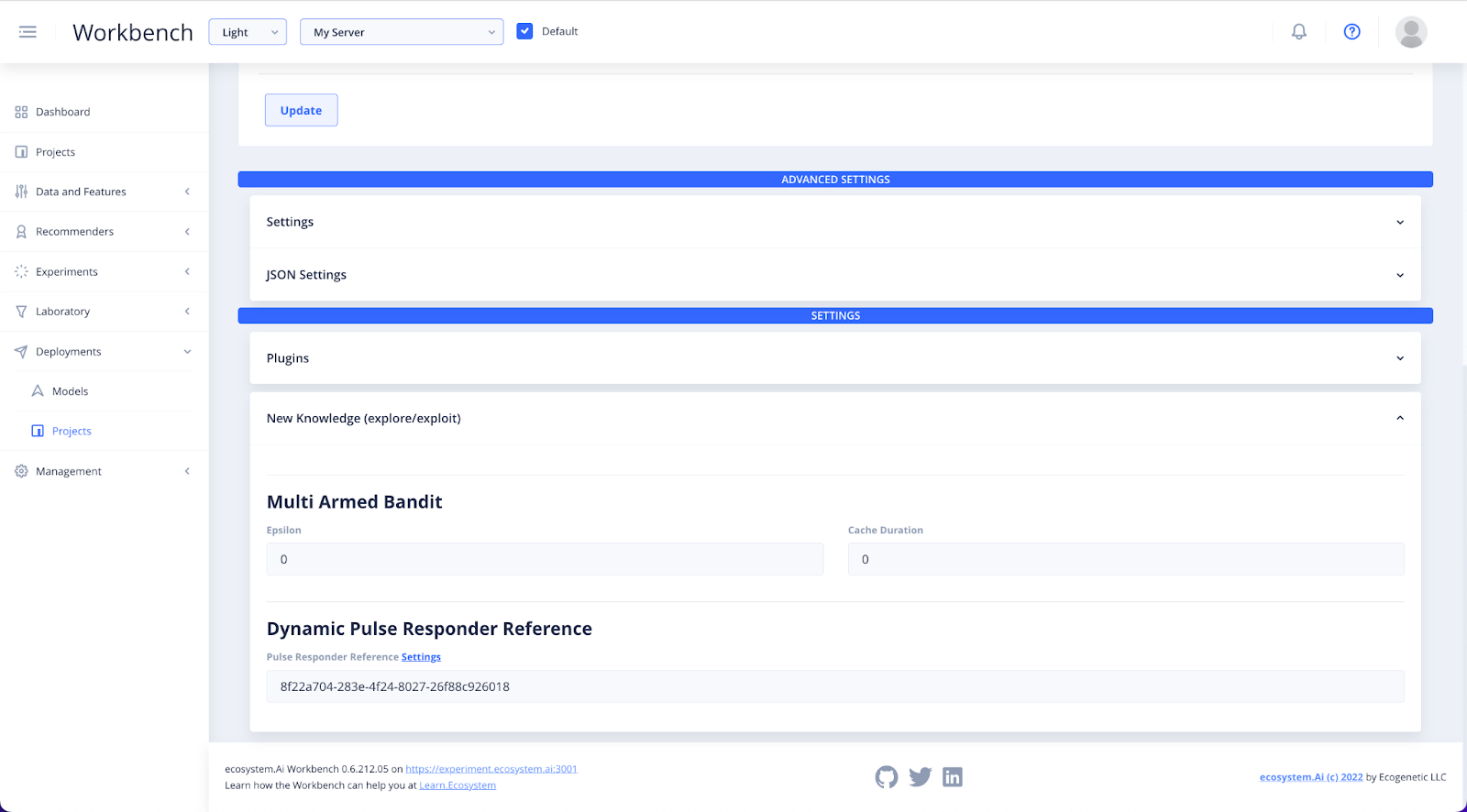
In Pulse Responder Reference set the UUID of the experiment configuration that you are going to push to production.
Click on the UUID in the field and click out again to validate the dynamic parameter.

You don’t need to worry about the rest of the fields, but it is suggested that you set the epsilon to 0 for most experiment setups.
There are a range of different Prediction Activators that can be selected to enhance the functionality of your deployment.
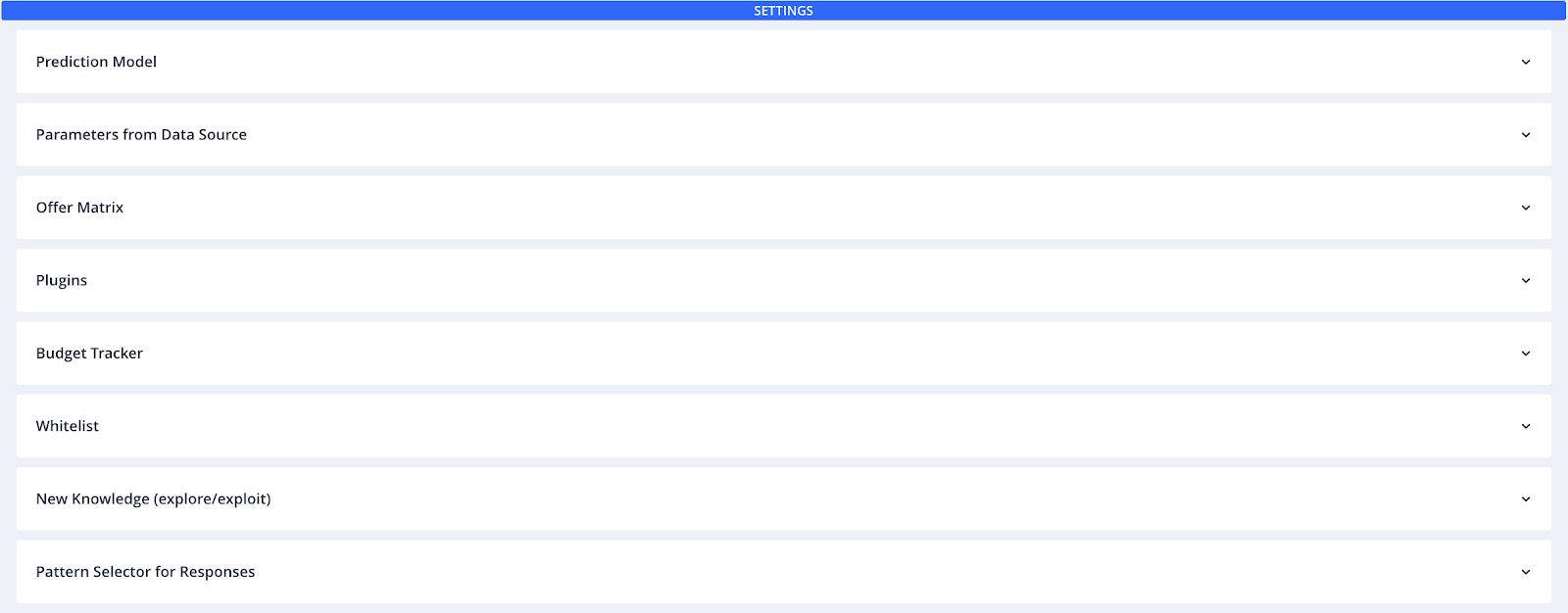
- Offer matrix is loaded in memory and accessed in the plugins. For the purpose of default pricing, category and other forms of lookup.
- Plugins supports three primary areas: API definition, pre-score logic and post-score logic. There are a number of post-score templates.
- Budget Tracker to track offers and other items used through the scoring engine, and alter the behavior of the scoring system. Must include the post-score template for this option to work.
- Whitelist allows you to test certain options with customers. The results will be obtained from a lookup table. Must include the post-score template for this option to work.
- New knowledge allows you to add exploration to your recommender. This will happen by specifying the epsilon parameter. Epsilon% (eg. 0.3 = 30%) of the interactions will be selected at random, while the remaining ones will be selected using the model.
- Pattern selector allows different patterns when when options are presented, through the scoring engine result.
For more detailed descriptions, go to the Prediction Activators documentation.
Update your Deployment.

When you are done with your deployment configuration, select Push to set the deployment up in your specified environment. No downtime is required.
The Generate and Build buttons are not needed for now, they are designed for Enterprise and on-premise setups.

Testing #
Once you have pushed your deployment configuration you should do some testing to see if the results align with your expectations. There are two ways to test your deployment:
Test your API
In the Laboratory section of the Workbench, you will find Manage APIs. Here you will find a list of all your deployments.
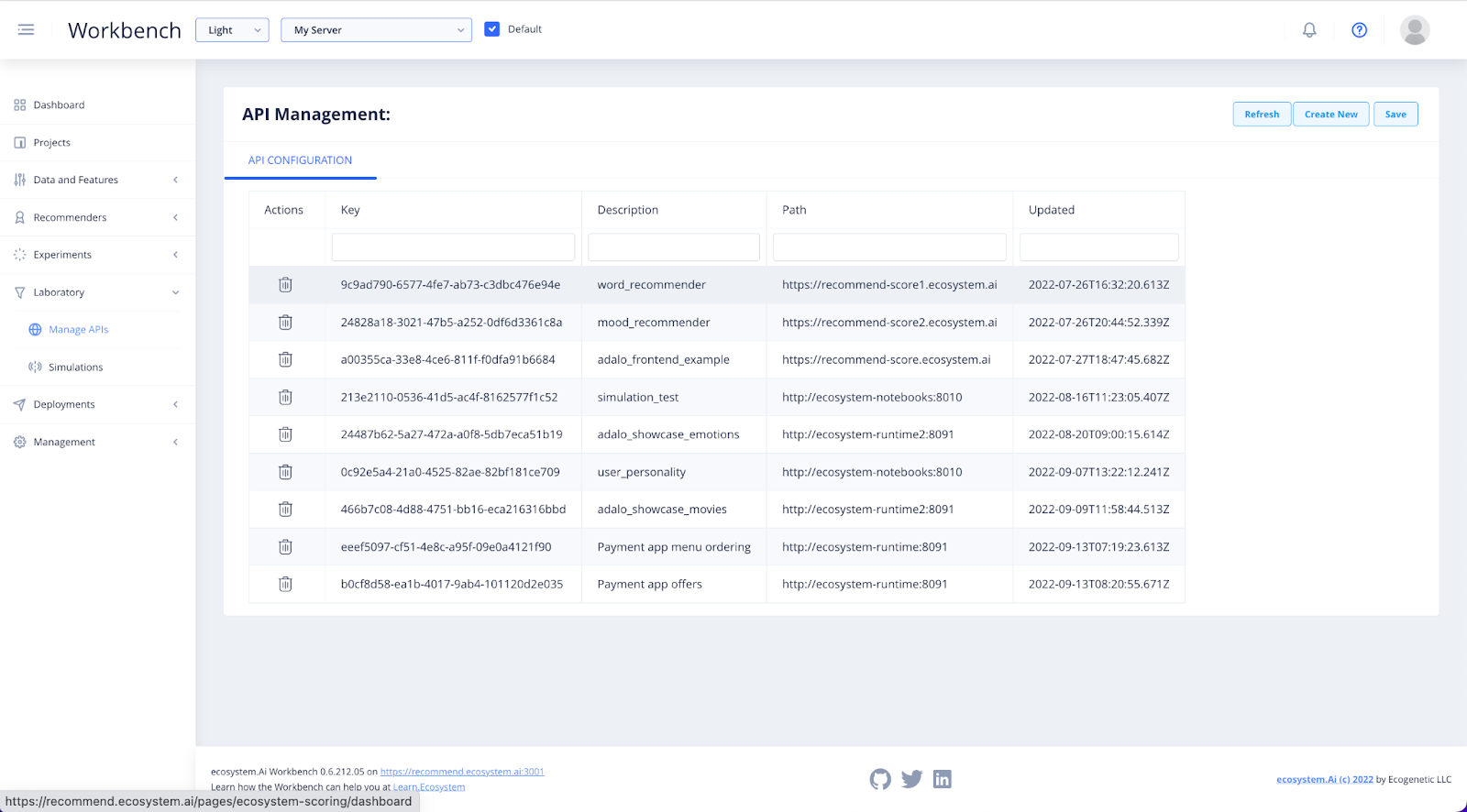
If you have been going through this Get Started using one of the pre-configured examples, click on the relevant deployment to view the details.
If you have created your own Project and deployment, select Create New to make a new API.
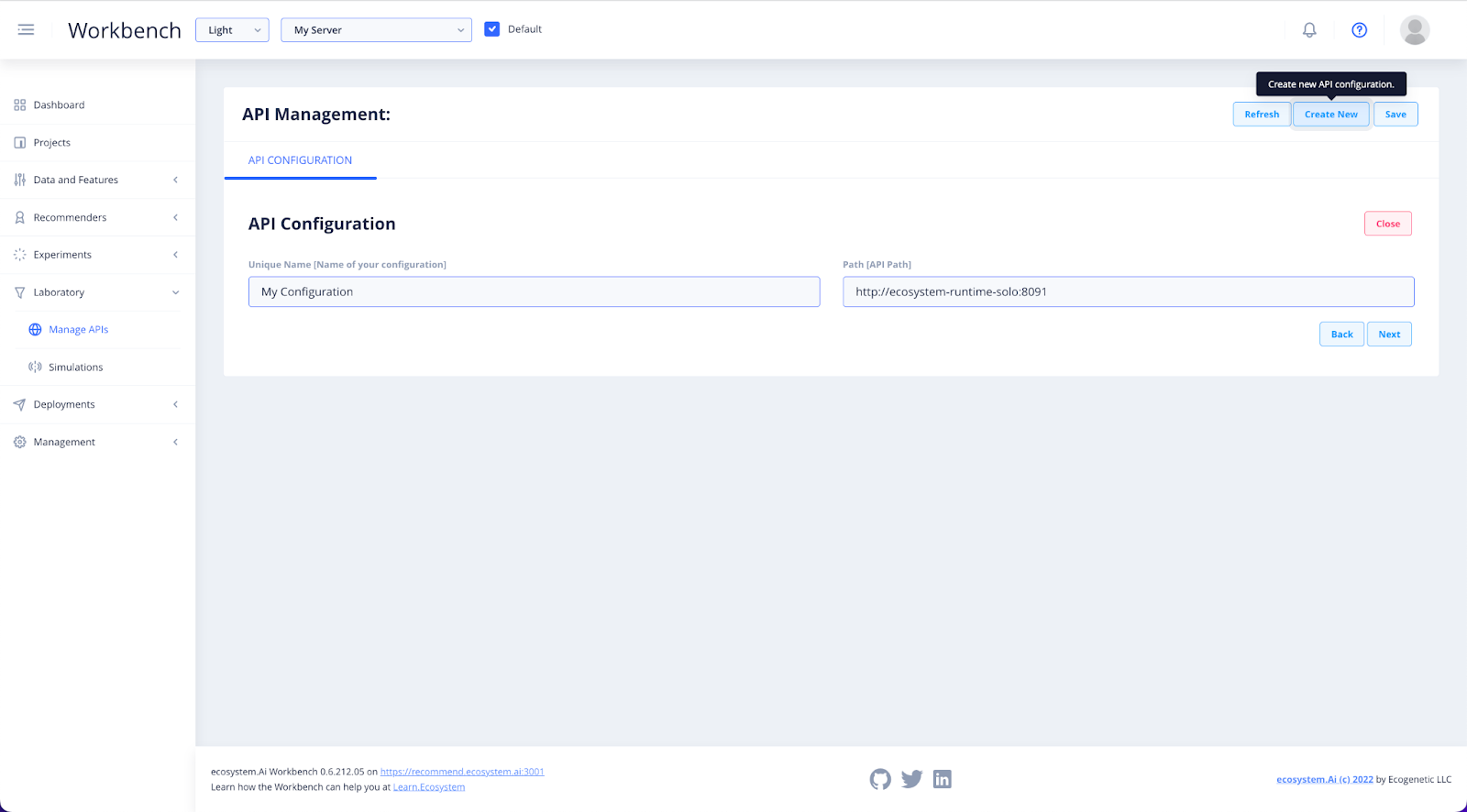
Provide the Unique Name of your deployment and click Next to add it to the list.
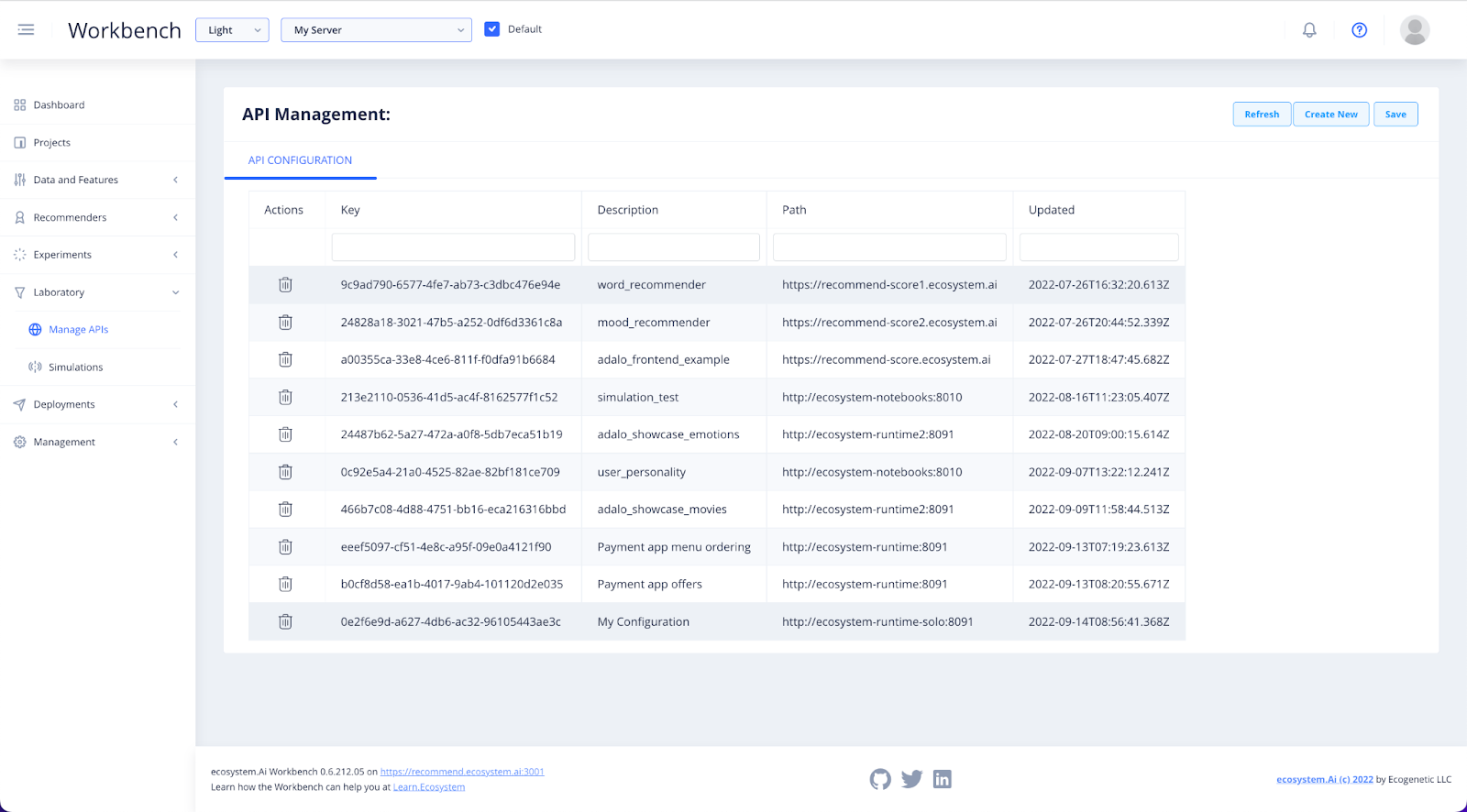
Select the configuration to view and edit the details of your API. Go to the Configuration tab and select the one you want to test.
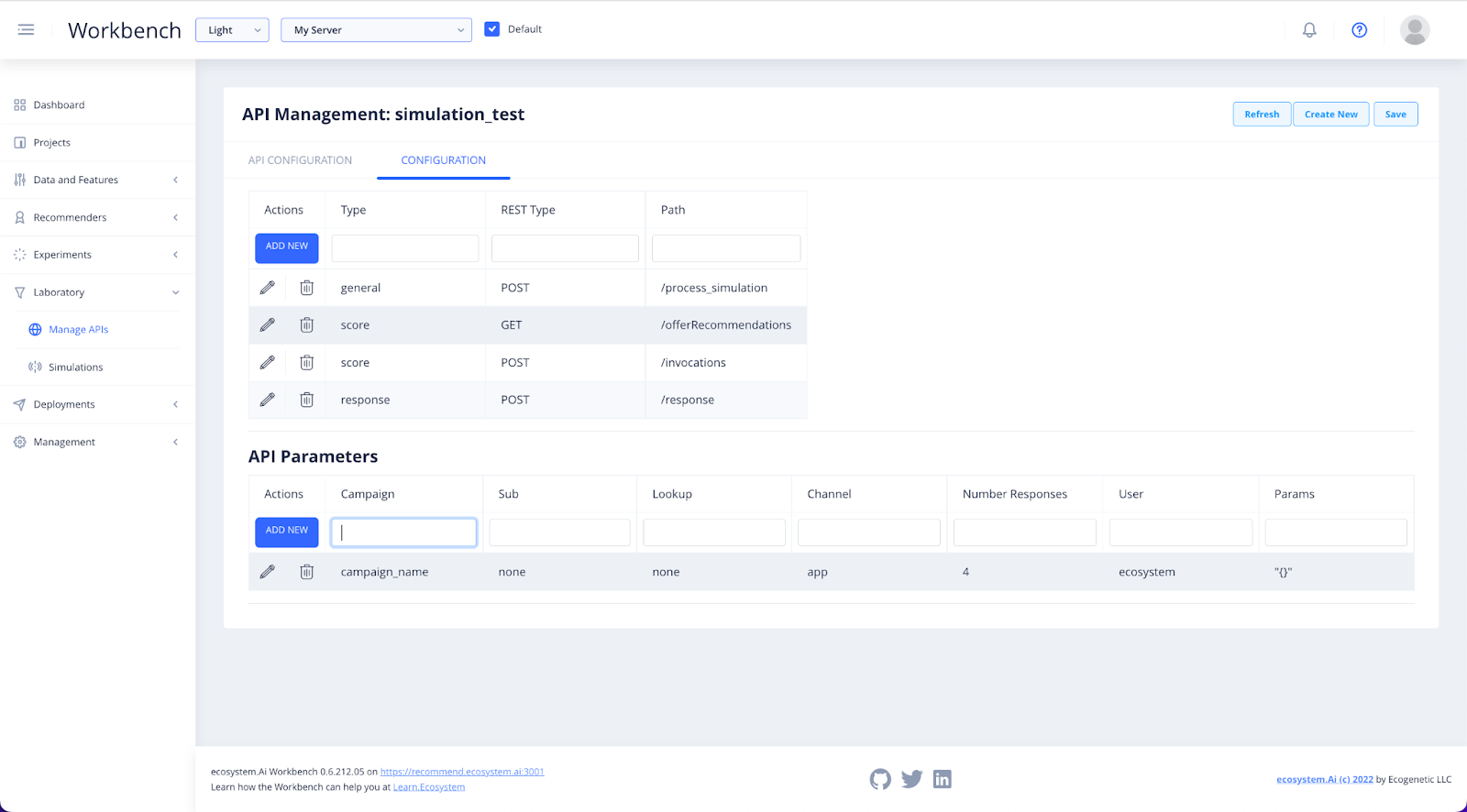
Fill in the relevant details of the campaign, then click on the campaign to bring down the API test window.
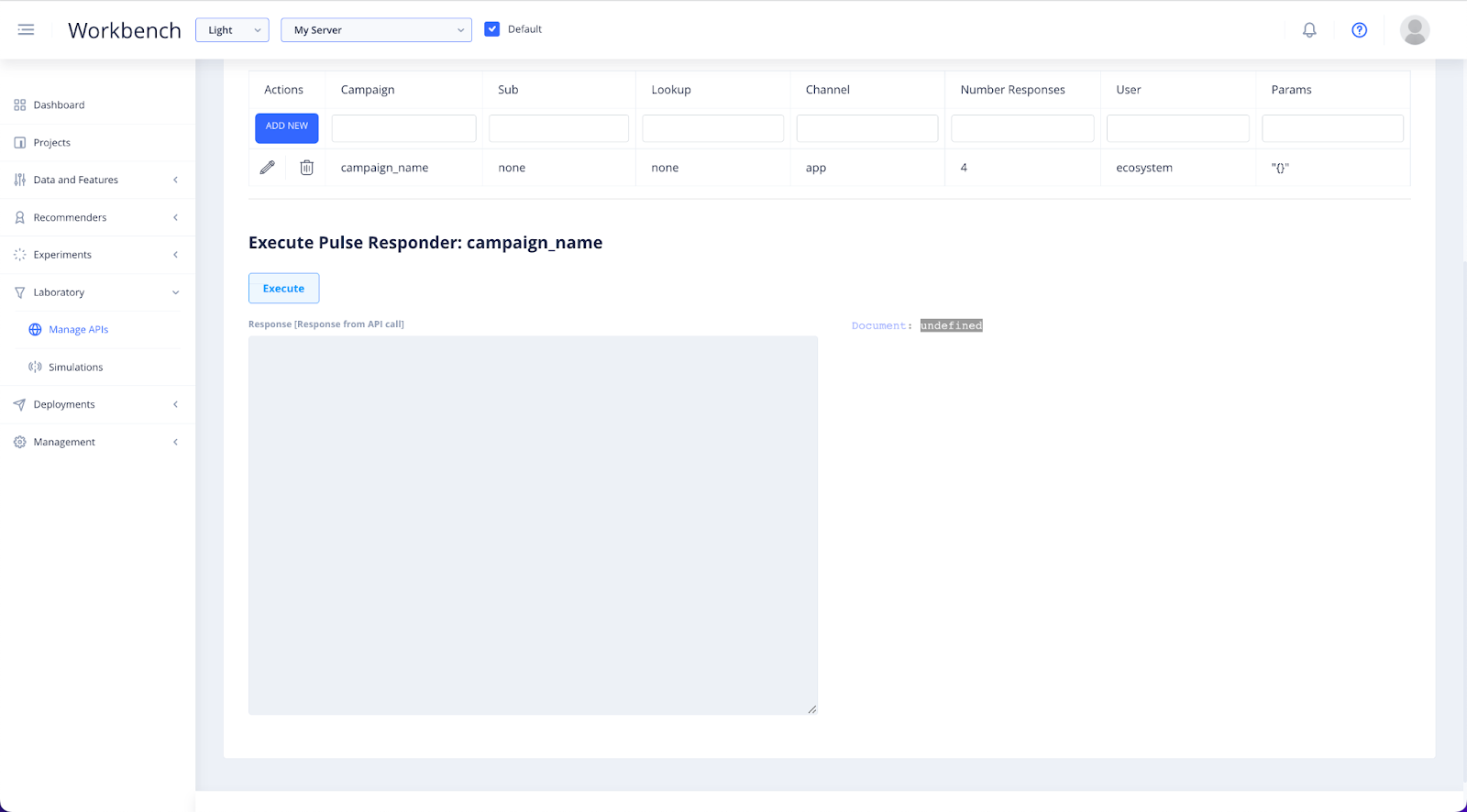
Click Execute to bring back the API results and ensure your deployment is functioning
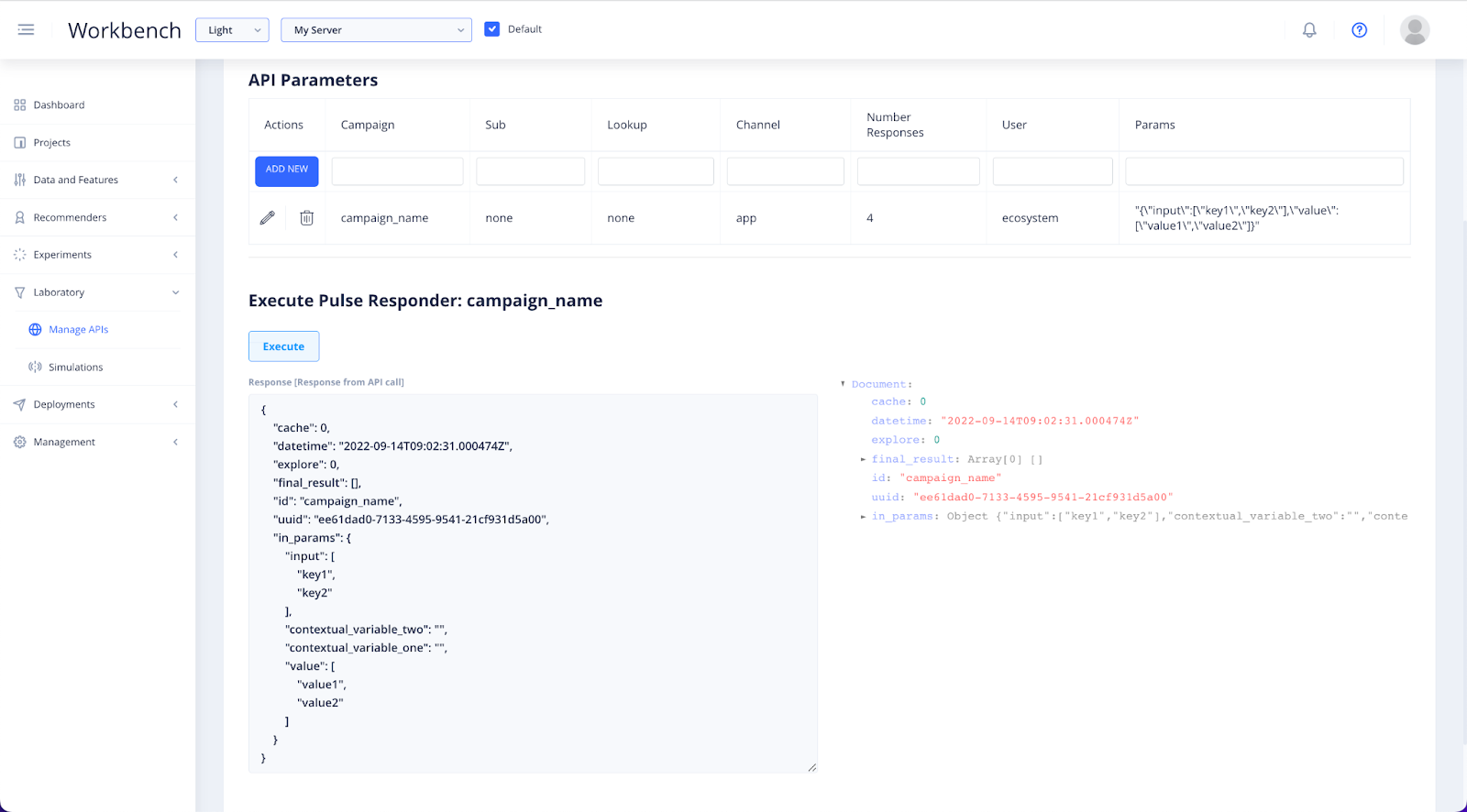
Now that you have built, deployed and tested the configuration of your recommender, it’s time to watch it in action.
Build a simulation
In your Dashboard you will find the Worker Ecosystem with links to various accompanying elements.

Click on the Jupyter Notebooks to configure the simulation of your experiment deployment. The steps of how to complete this part of the journey is laid out in the Notebooks.

Monitoring #
Once your experiment is running it is important to keep track of its behavior, and begin to examine the results. There are two dashboard softwares we have linked up to be accessible in your worker ecosystem:
Real-Time Grafana Dashboard
In the Dashboard of the Workbench, select the Real-Time Dashboard icon to go to Grafana, to set up and view the real-time results of your deployment.
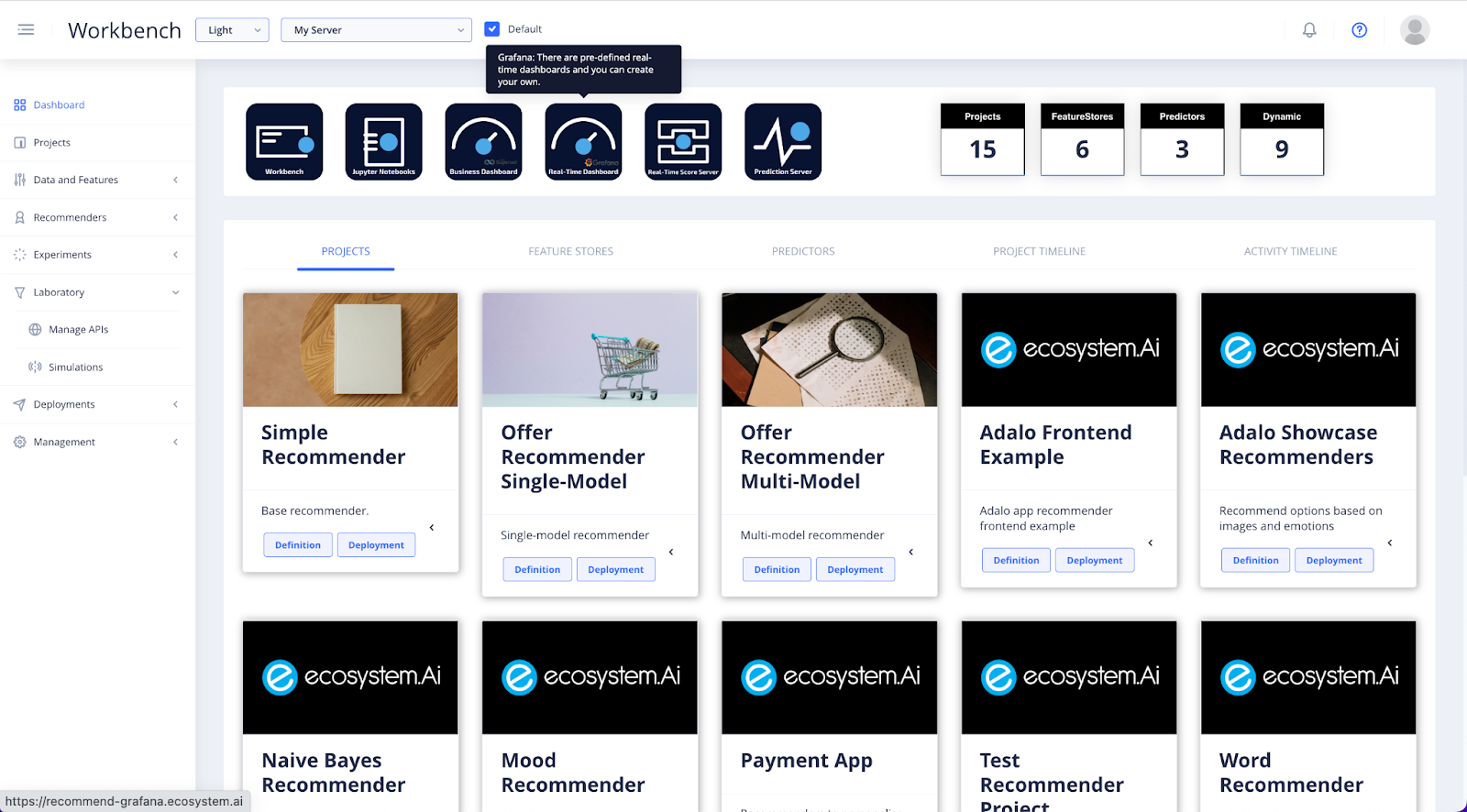
Access the Grafana Dashboards for a real-time view of your experiment.
Our Grafana Dashboards illustrate the behavior of the experiment in production. Showing which options are being shown, and which are successful. As well as providing information on performance, and how the experiment is exploring.
To set up your Grafana Dashboard, and link it to your chosen deployment, you will need to login as an admin. We have already pre-built a dashboard for you to view all the most important elements of your real-time deployment. However, if you have experience with Grafana, or are looking to monitor something very specific, you can build your own dashboard: https://grafana.com/docs/grafana/next/getting-started/build-first-dashboard/.
Now that you have logged in, Navigate to the left hand menu, click on the ‘dashboards’ icon and select Manage.
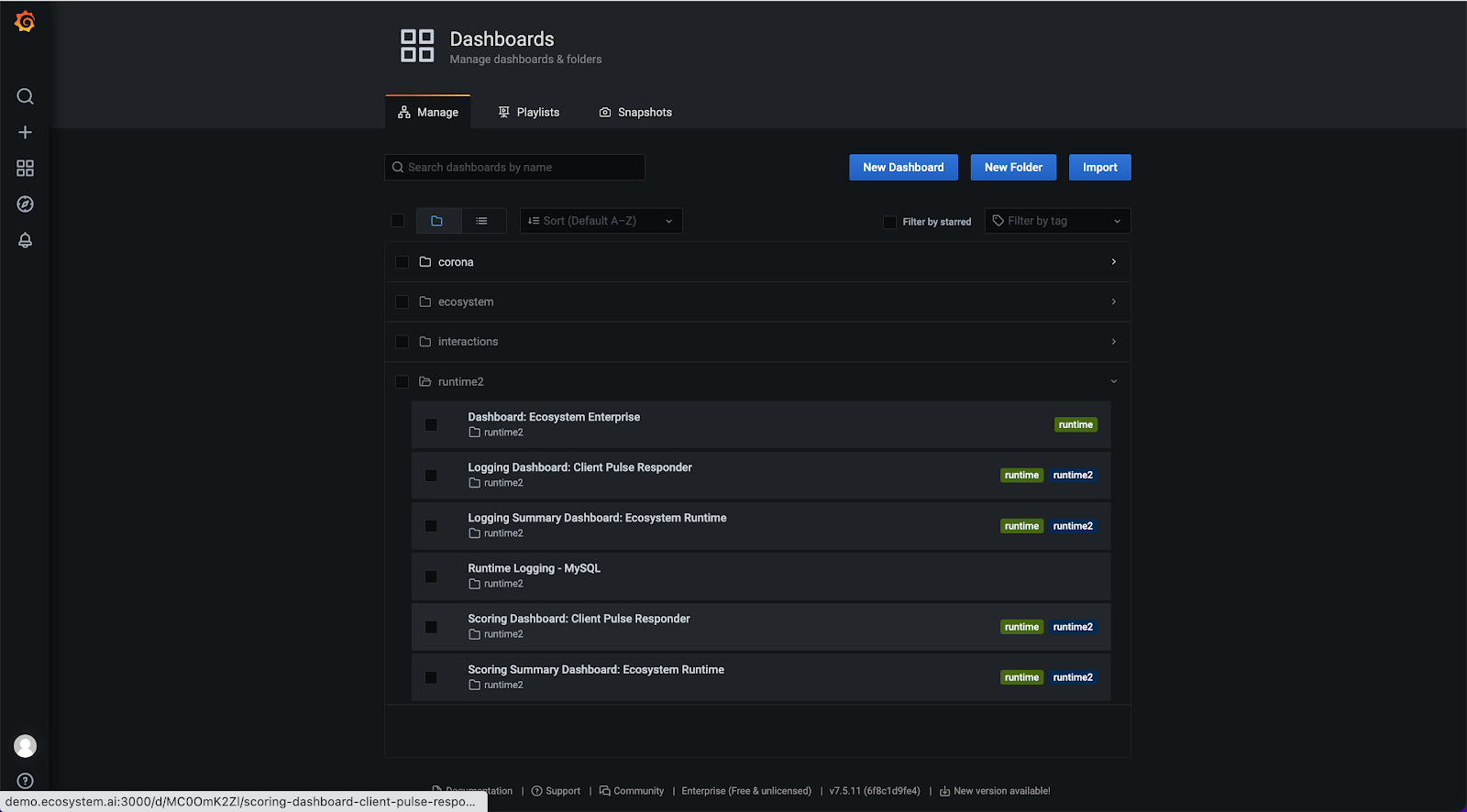
At this point, you will see a list of folders. Select the Runtime2 folder and click on Scoring Dashboard: Client Pulse Responder.
To view the pre-built dashboard configuration. The dropdown menu called Prediction case is where you can see all the deployments linked to this dashboard. Find your Deployment there if you have used one of the pre-configured solutions.
To add a new deployment, go to the Dashboard Settings icon in the top right corner.
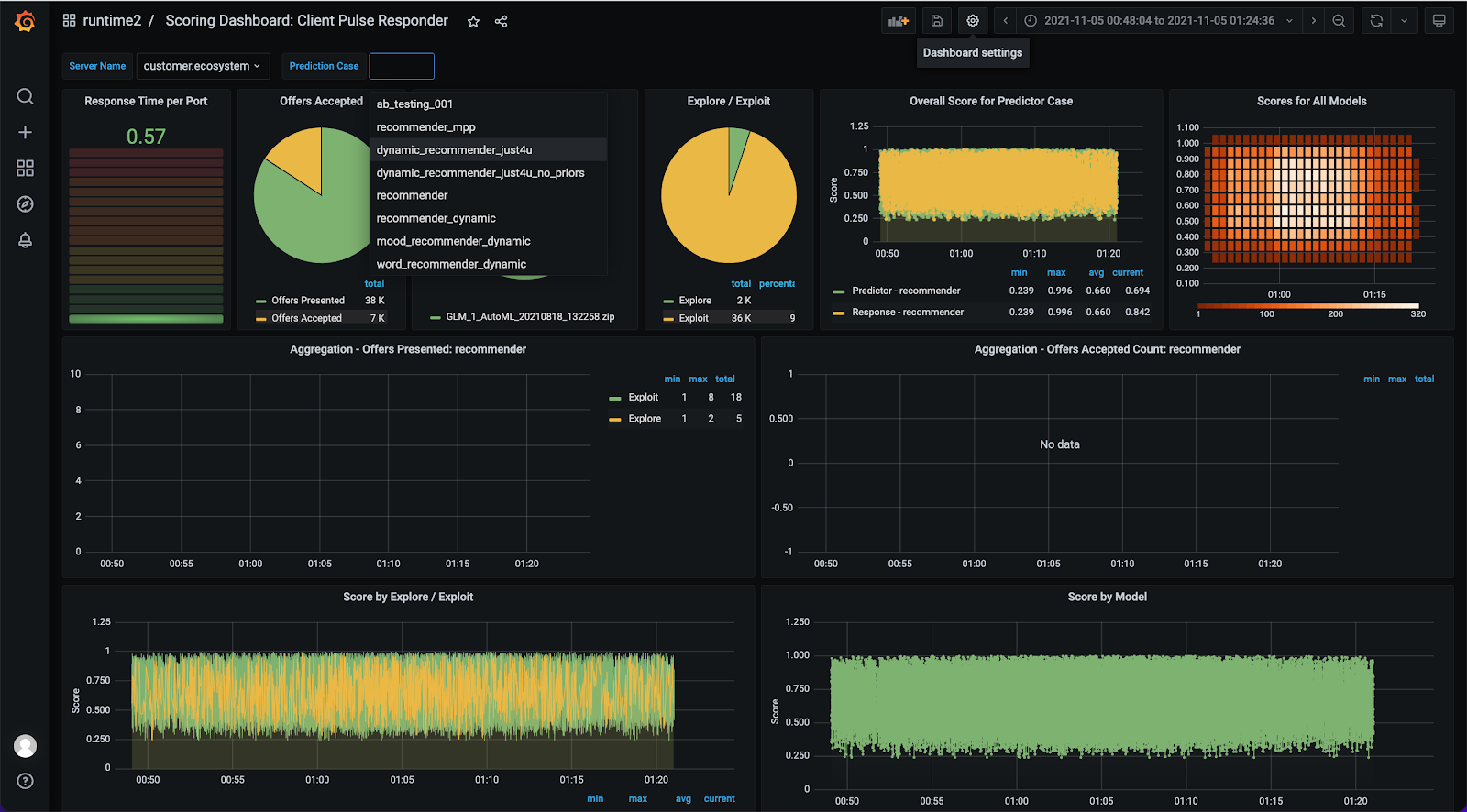
This will take you to the settings page where you can manage elements of the dashboard.
Go the Variables in the menu on the left, and then click on Prediction.
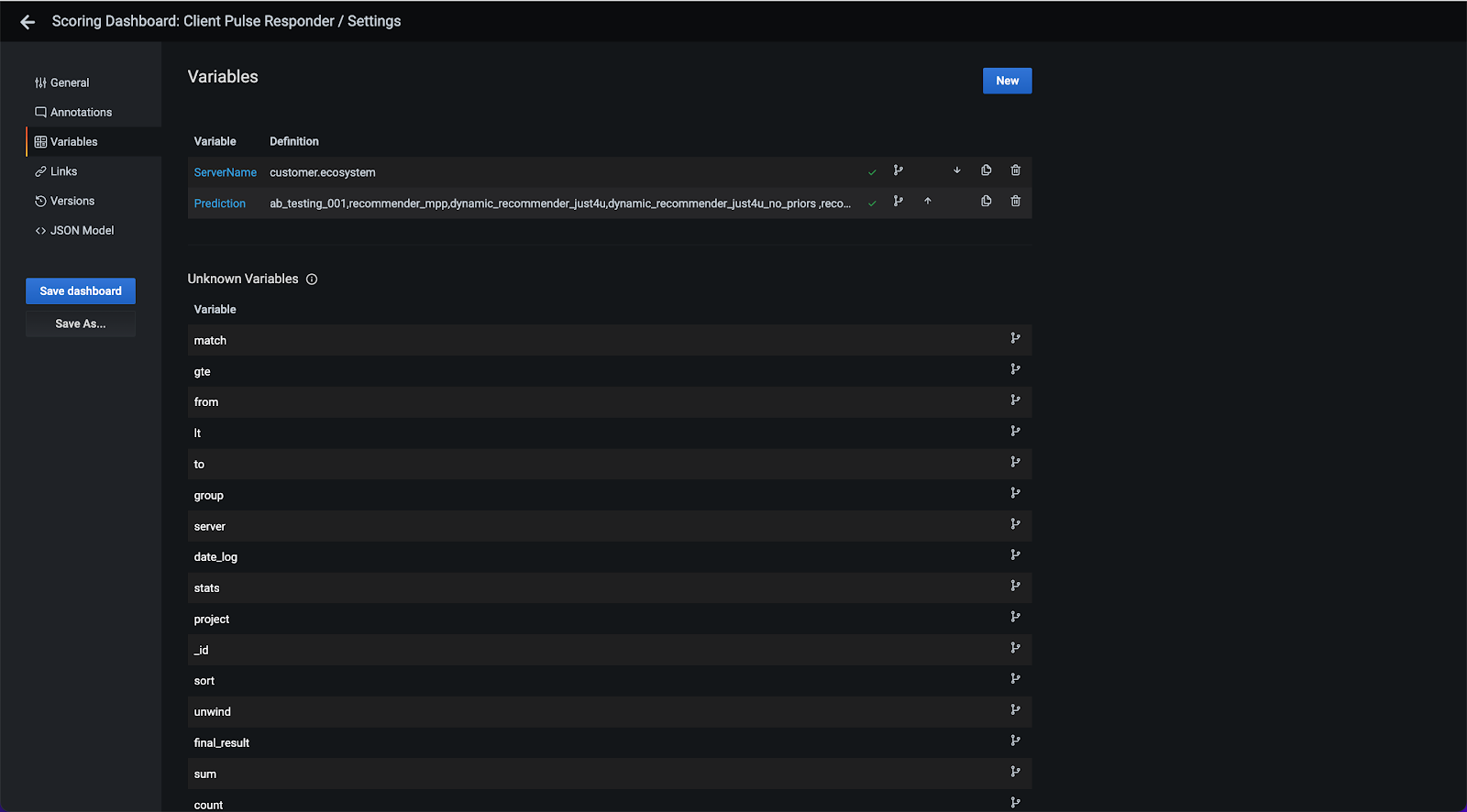
You will notice in the Custom Options field that the deployments currently linked to this dashboard are listed, separated by commas.
Simply add your deployment case name in this field.
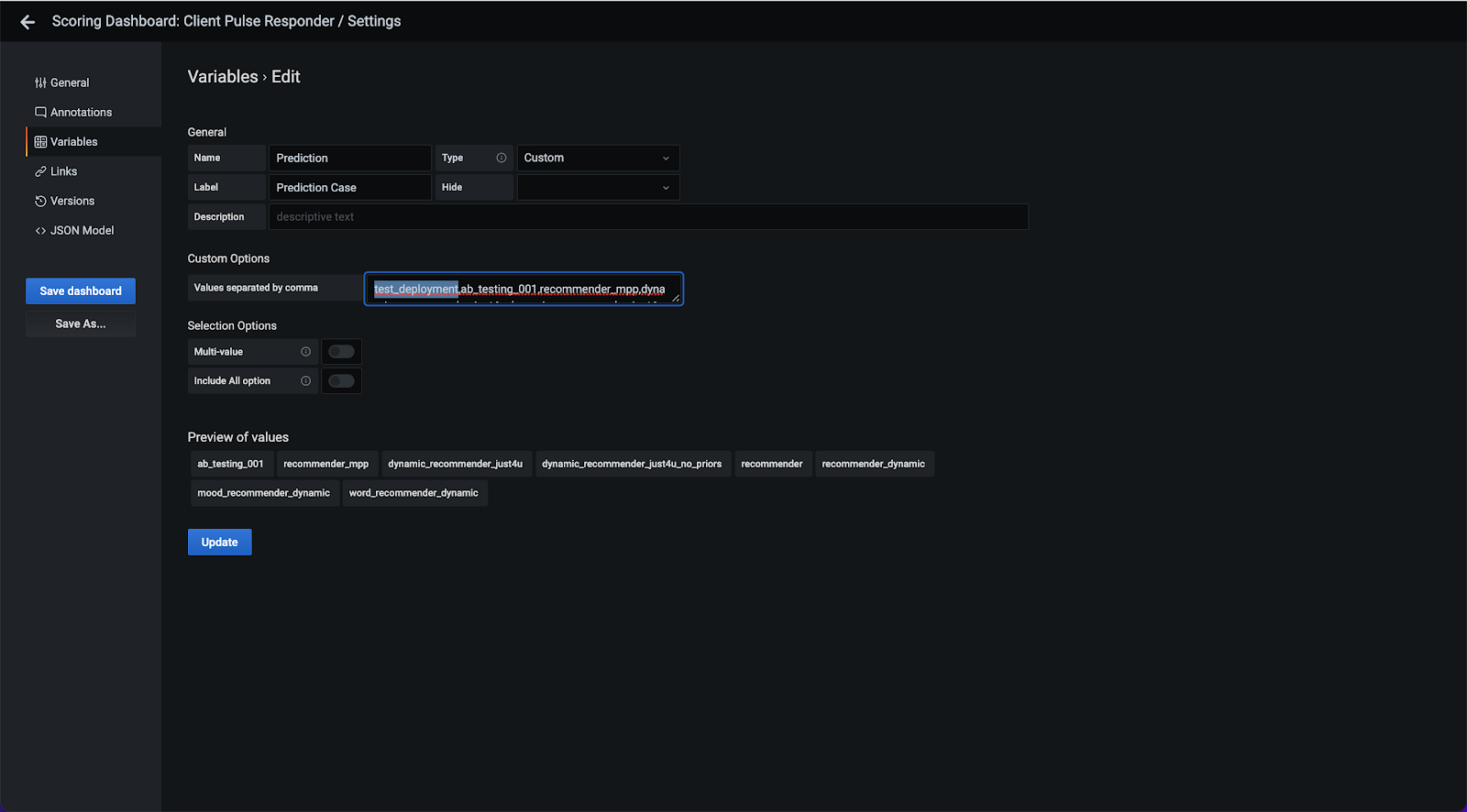
Then click Update. When this refreshes, click Save Dashboard on the left, this will link to a popup where you can specify the details of your changes. This is not a compulsory step, but it is good practice to document all changes.
Then click Save. Press the back button in the top left hand corner to go back to the dashboard, give it a minute to load and then you will be able to view your new deployment in the Prediction Case list.
Superset Business Dashboard
To prepare your Dashboard, navigate to Management and go to Utilities. Using the Utility Option dropdown, select the Prepare Dashboard option. Click Process, then head over to Superset.
In the Dashboard of the Workbench, select the Business Dashboard icon to go to Superset, to view more comprehensive results of your deployment.
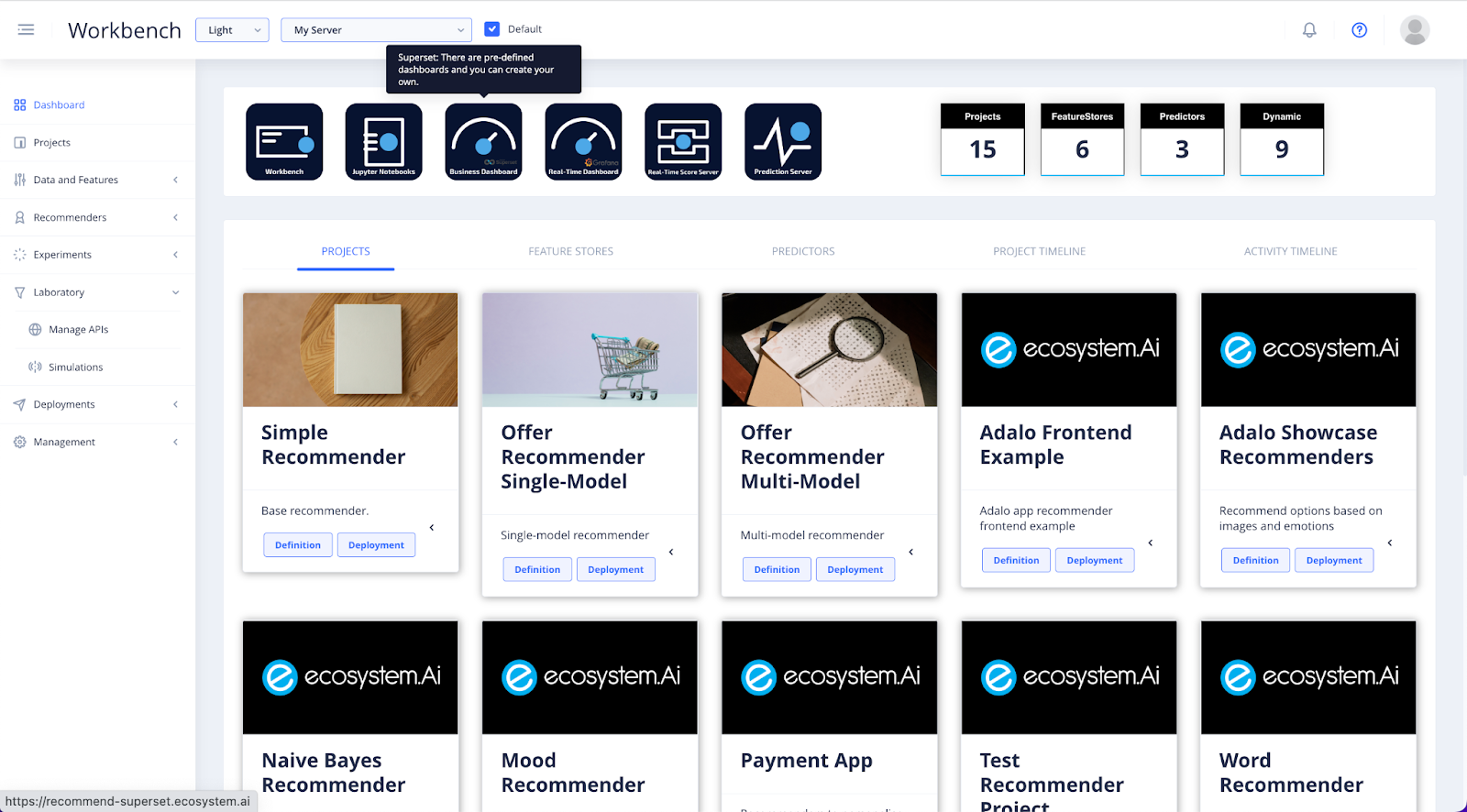
Access the Superset Dashboard to view further illustrations of your recommender in production.
The superset dashboards allow you to view and analyze the results of the whole experimentation process out of production. You can look at results either before production, during production and post-production. Superset allows you to view all the details of your experiments in the same place.
Once in Superset, use the menu to navigate to Dashboards, there you will find a list of pre-configured dashboards you can view and play around with. To view the dashboard you have prepared from the Workbench, first select Experiment Details.
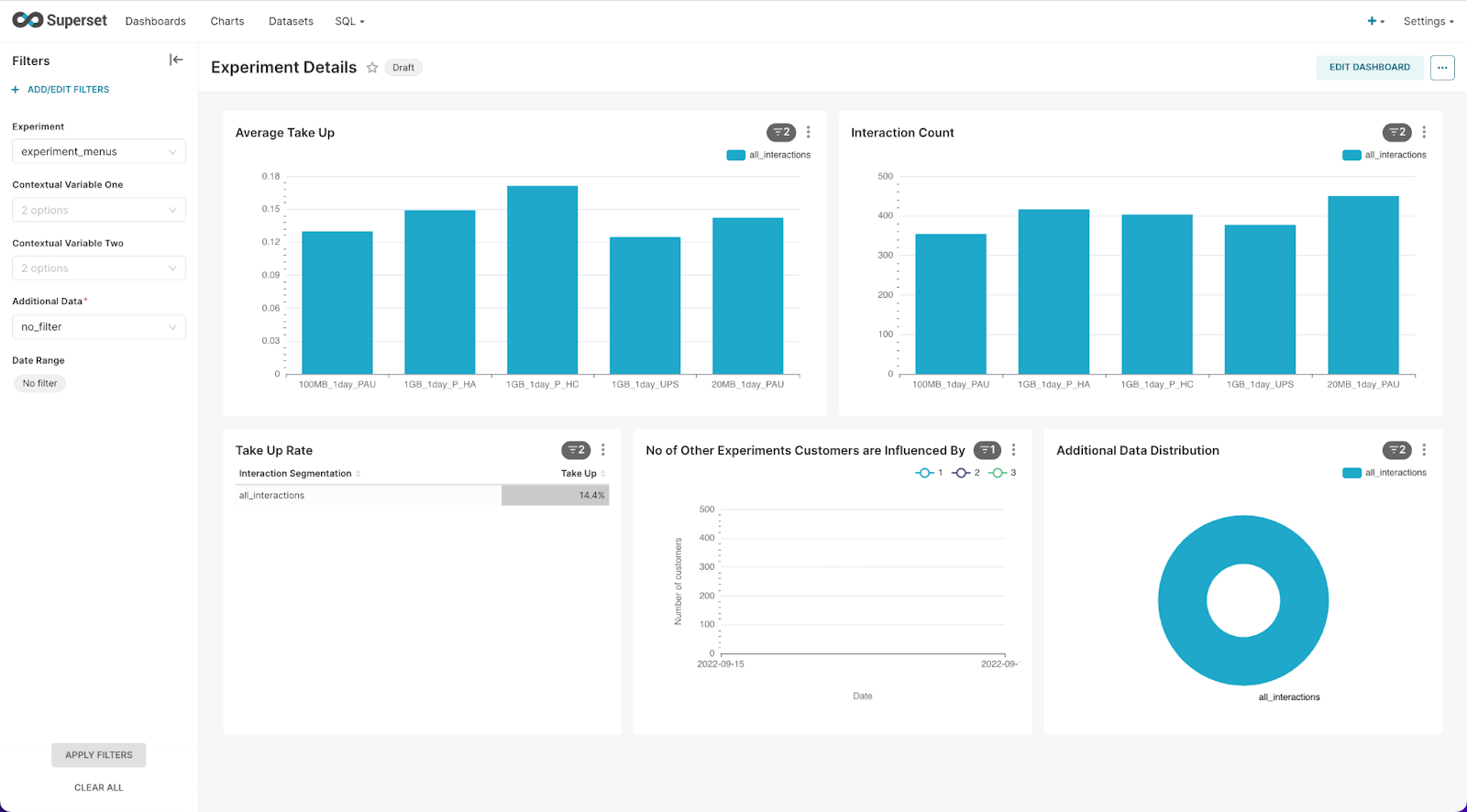
It will have automatically selected an experiment to show you. Use the panel on the left to then select the experiment you wish to view. Once you have chosen your preferred experiment, click Apply Filters to load it.
There are a series of dash windows you can view various experiment details such as Average Take Up, Interaction Count, and No. of Customers Influenced by Other Experiments.
In this Dashboard, you can set a series of filters, such as time of day or other contextual variables you may have configured into your experiment.
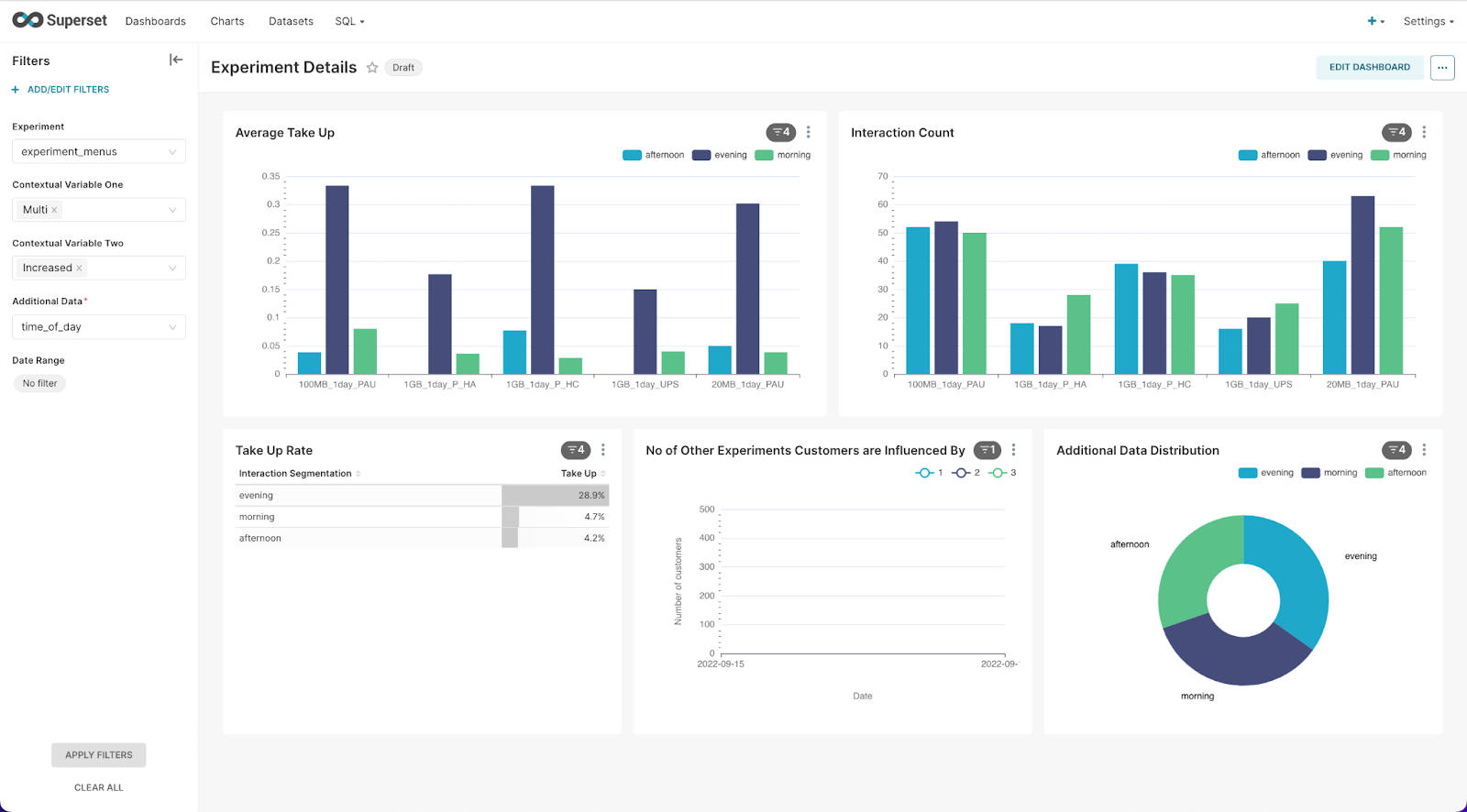
Once you have viewed your Experiment Details dashboard, you can go back to your Dashboards list and find Experiments Overview.
Congratulations! You now know how to set up a No Data Experiment #
Advanced Settings for Engagement – Dynamic Pulse Responder Configuration


Leave A Comment
You must be logged in to post a comment.