The precise origins of A/B testing are hard to determine, but it they are known to have predated computers by several decades. Statistician and biologist Ronald Fisher was the first researcher known to implement A/B testing, also known as split-testing, in the 1920s – and he used it to optimize agricultural practices. Splitting crops randomly into control and test groups, he set out to determine the effects of different conditions on crops, as well as the efficacy of fertilizers. At this time, the idea that experimental treatments should be randomized was a revolutionary idea.
Despite these seemingly rudimentary beginnings, A/B testing took off in the software world. In 2012, a Microsoft employee working on the search engine Bing created an A/B experiment to test the display of different advertising headlines. Within hours, the alternative format saw a revenue increase of 12%. Today, major software companies such as Microsoft and Google continue to conduct over 10,000 A/B tests annually.
Multi-armed Bandits for Contextualization
The attraction to A/B tests has long been based on their ability to fetch concrete results in the short-term, but you will soon see that they fall short of optimizing long-term results. While A/B tests were effective in a simpler era of the internet, the environments in which they now operate have changed dramatically. With technology sitting in our pockets and moving with us through the world, digital interactions have shown a corresponding increase in dynamism. The way humans interact with technology has started to mimic that of real-world interaction, with increasing expectations of near real-time response, and content that is not only personalized but contextualized. This means interactions need to take far more factors into account – not just personal preferences, but time of day, day of week, location and recent actions. Experiments that assume the world is static can’t keep up with such fluid variables.
Because A/B tests have to run for long enough to reach statistical significance (often painfully long), you lose time while confirming something that may not matter anymore once the experiment has been completed. Additionally, the declared “winner” may perform best among the options you tested, but that tells you nothing about all the options you didn’t test. This means that not only do you lose time, but your results are not guaranteed to represent optimal performance. This brings us to the elusive multi-armed bandit.
Not as simple as A/B
Imagine you walk into a dark landscape with a flashlight. You move the light around until it hits the rising slope of a small hill. You assume that the hill is the highest point in the landscape – but fail to recognise that you are only looking in one place.
In multi-armed bandit experiments (MABs), the closest high-points you observe are called local optimas, and the methodology ensures these aren’t mistaken for ‘the best you can do’.
As explained by our developer Ramsay Louw, with the help of trusty Paint software, MABs point the flashlight at several different points in the landscape. They achieve this by initially making random offers to determine the general shape of the environment – where are some of the known highs/known lows? MABs will then generally continue to explore more in the vicinity of a high point, or ‘local optimum’, to see just how high of a result it can fetch. While doing this, it will also incorporate some more random offers beyond just option A or B, to ensure it is still considering the unknown. The variety of tactics are known as the bandit’s ‘multiple arms’. Choosing which arms to allocate traffic to is dictated by the explore/exploit tradeoff, where exploring is random sampling of different arms, and exploiting is persisting with known winning arms.

A Multi-armed Bandit
In sum the explore/exploit tradeoff looks like:
Explore:
- Try other options.
- Avoid being stuck in a local optimum.
- Adapt when the world changes (seasonality, trends, behaviours).
Exploit:
- Show more of whatever looks best so far.
- Get good short-term results.
MABs are used in the background of many personalization strategies. Let’s consider MAB testing in recommender systems. Our Dynamic Recommenders, using MABs, do not aim to find a universal winner (as with A/B tests). Rather, they aim to find the best option for a particular person, in a particular context at a particular time. This quality makes multi-armed bandit methods indispensable for real-time hyper-personalization and contextualization.
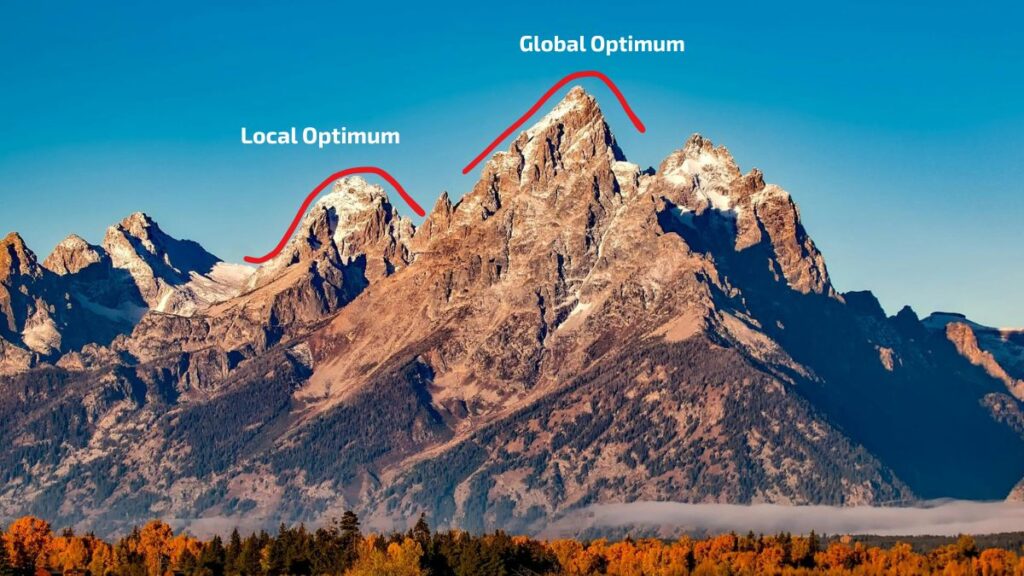
Caption: Multi-armed Bandit (MAB) tests take samples randomly across distributions, resulting in a series of local optimas with one overriding global optimum representing the distribution (arm) with the highest expected long-term reward across all options.
This is because MABs assume that, while a certain offer might perform well in a certain area, this may not be the best performance it could achieve. In engineering, “a local optimum is a solution that is the best within a specific, limited area of a problem space but is not necessarily the best overall solution, which is the global optimum”. This means that you can optimize parts of the system as much as possible, while still missing the best performance for the whole system.
In digital interactions, contexts shift from one moment to the next, which means the position of the global optimum in one moment will shift in the next. This means you need a system that can constantly evaluate the performance of a variety of options dynamically, rather than assigning them to specific, static contexts. MABs handle this by constantly balancing between exploring and exploiting, and dynamically adjusting traffic allocation to best options. They’ll recognise an offer is performing well, and allocate more traffic to that offer, reducing the screen time of less-than-optimal options.
While bandits are more complex and involve more logic, compared to A/B testing they:
-
- converge dynamically, rather than waiting for statistical significance.
- waste less traffic on bad options, because they learn from failures and automatically re-allocate traffic to better options.
- learn as you test and dynamically allocate traffic, while A/B tests require manual intervention once a statistically significant winner is found.
- test for maximum performance, not simply a difference between two variables.
Conclusion
The practice of standard personalization no longer goes far enough, considering that consumers’ relationship with technology has changed. Technology has become a mobile tool for interfacing with the world as we move through it. Multi-armed bandits allow your systems to adjust dynamically and make every interaction contextualized, pushing performance metrics further than traditional methods ever could.



")