Prediction is a key element of the work of Computational Social Science. Why? In a company environment, implementing actions based on accurate predictions creates opportunities for generating and maintaining competitive advantage. It can become a key driver to propel you to success over your competitors.
But before examining the value of Computation Social Science and prediction, it’s worthwhile considering the relationship between humans and prediction. We have attempted to predict using many different methods over the ages, but invariably we don’t get it right.
Weather prediction for example, presents an interesting set of challenges i.e. dynamic changes over time based on a multitude of changing variables. Today’s three-day forecasts are as precise as the two-day forecast ten years ago. We’ve learnt that it’s not only about the data and computational power. It’s about the concept of prediction, or the concept of prediction-philosophy that changes over time.
Firstly, is one’s view of the past an effective basis for predicting the future? It might be tempting to think that past experience provides a reliable basis for extrapolating the future, but this is not the case.Consider two notable quotes illustrating the point:
“There is not the slightest indication that nuclear energy will ever be obtainable. It would mean that the atom would have to be shattered at will.” — Albert Einstein, 1932
“Heavier-than-air flying machines are impossible.” — Lord Kelvin, British mathematician and physicist, president of the British Royal Society, 1895
There are a number of very human reasons why a view of the past isn’t a reliable yardstick for the future. Consider your ability to remember details about events as you move through life. The process of ageing comes with some real-life side effects like memory loss. Even your cultural biases change over time. People form a conceptual or inaccurate view of the past, and thus a conceptual, inaccurate definition of the future gets created.
Secondly, if institutions requiring accurate predictions can’t rely on humans, can they rely on humans with tools that take the long view? In latter case, predictions are made by humans using data and statistical methods. Unfortunately results get frozen in time and form a reality for the people using these results as it’s implemented (credit scoring, for example).
But in an emergent world, innovation is dynamic and rapidly evolving, where we need predictive models that use a more real-time approach. Using intelligent prediction approaches where you use artificial intelligence to predict which machine learning model is most appropriate, you can calibrate predictions continuously. This allows for the inclusion of changes as humans evolve over time.
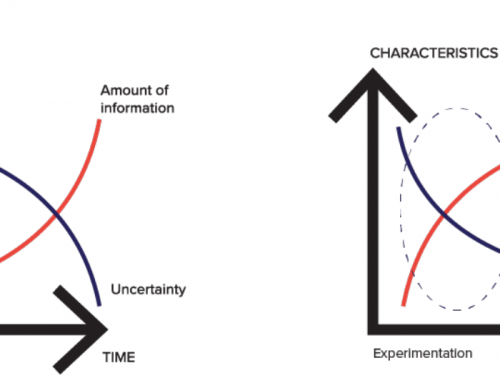
Predicting the next hour is much simpler than predicting the next year, because as external elements change one is able to catch the emergent waves. Institutions thus need predictive tools that recalibrate daily and in certain cases forget previous learnings. It’s about learning about the error in learning.
Being emergent as an element of successful prediction, also requires data that uses social science constructs. This provides companies such as ecosystem.Ai with a much better understanding of how people will or won’t behave, and assists in predicting what they’ll do next.
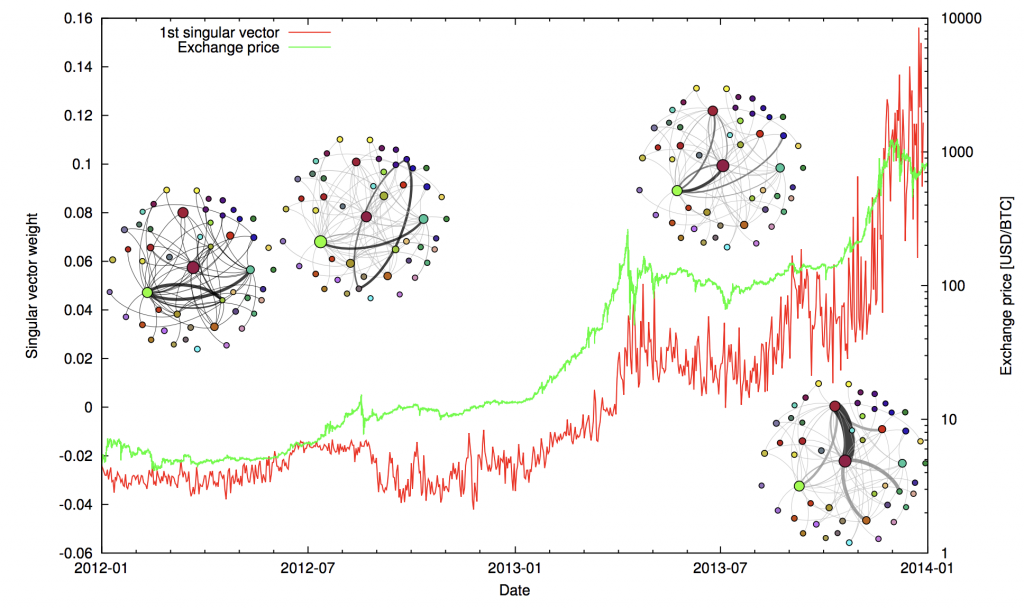
Distributed ledgers and networks present a number of opportunities for analyzing shifts in sentiment, manipulation and other social triggers. Since all the data about the transaction is public, we can infer a number of predictive outcomes. What is price of “hype” and the emotions that an individual experiences while being excluded from a network of participants? Can we predict, using blockchain, bitcoin, and other public data sets, if an individual will participate in financial transactions based on their life situation? Could we determine the risk profile of such an individual in their networked setting?
Overlaying a multitude of prediction models and approaches, ultimately should produce a simple “yes” or “no”, or in other situations, might produce the next buying action over space and time. Getting from data to the most appropriate prediction, is the journey we’re on. The “Master Algorithm” could be seen as an answer to all prediction problems, but we foresee more diverse and dispersed prediction processing capabilities developing over time.
Unlike humans, algorithms do not have the problem of predicting anything based on an “ageing brain”, or do not have an emotional response to the past. Rather, predictions are made based on the social philosophy the algorithm is addressing. For example, humans using money change dynamically over time based on their network, lifestyle aspirations etc. And so, finding value in data is not just about analyzing the results; it’s about using a prediction engine that understands that the delta’s created in predictions are based on a variety of human interests and emotions.
A successful outcome is the ability to predict human behavior using social science and behavioral sciences as constructs. Computational models assist in the analysis of data and provides a more predictable, and ultimately a more human-specific and useful, action. The prediction can never really be seen as “incorrect”, as the error in the human system is dynamic. Mapping behavior on a spectrum allows your actions to be more relevant. You just need to be more correct than your competitors about how you apply your predictions. Then learn, and un-learn, from them over time.